Este proyecto nació a partir de un ejercicio práctico en uno de los primeros cursos de análisis de datos que realicé. El ejercicio consistía en puntuar del 0 al 10 el índice de toxicidad de cada usuario usando como datos todos sus tweets. Me provocó mucha curiosidad ver cómo se habían extraído y guardado todos esos tweets y me puse a investigar.
Con los conocimientos de Python, web scraping y html que tenía intenté crear mi propio software de almacenamiento de tweets y entendiendo el código html de Twitter conseguí crear un bot que puede hacer prácticamente cualquier cosa en esta aplicación. Seguir masivamente usuarios a través de un hashtag, dar likes o retweets, almacenar todos los tweets que contengan una palabra clave en un archivo txt o incluso en una BBDD…
¿Cómo funciona?
Como ya he mencionado antes este proyecto tiene un mundo de posibilidades, con algo de tiempo para entender el código html de Twitter y lograr plasmar en el código tus ideas puedes conseguir lo que te propongas.
Si quieres promocionar una tienda de fundas para móviles por ejemplo podría modificar el script y conseguir que, de forma completamente automatizada, respondieras a todos los tweets de las principales marcas de móviles del mercado con una variedad de, por ejemplo, 200 tweets previamente escritos por tí o incluso por una IA y con intervalos de tiempo randomizados para que parezca lo más natural posible y sea indetectable para los sistemas de rastreo de spam del propio software de Twitter.
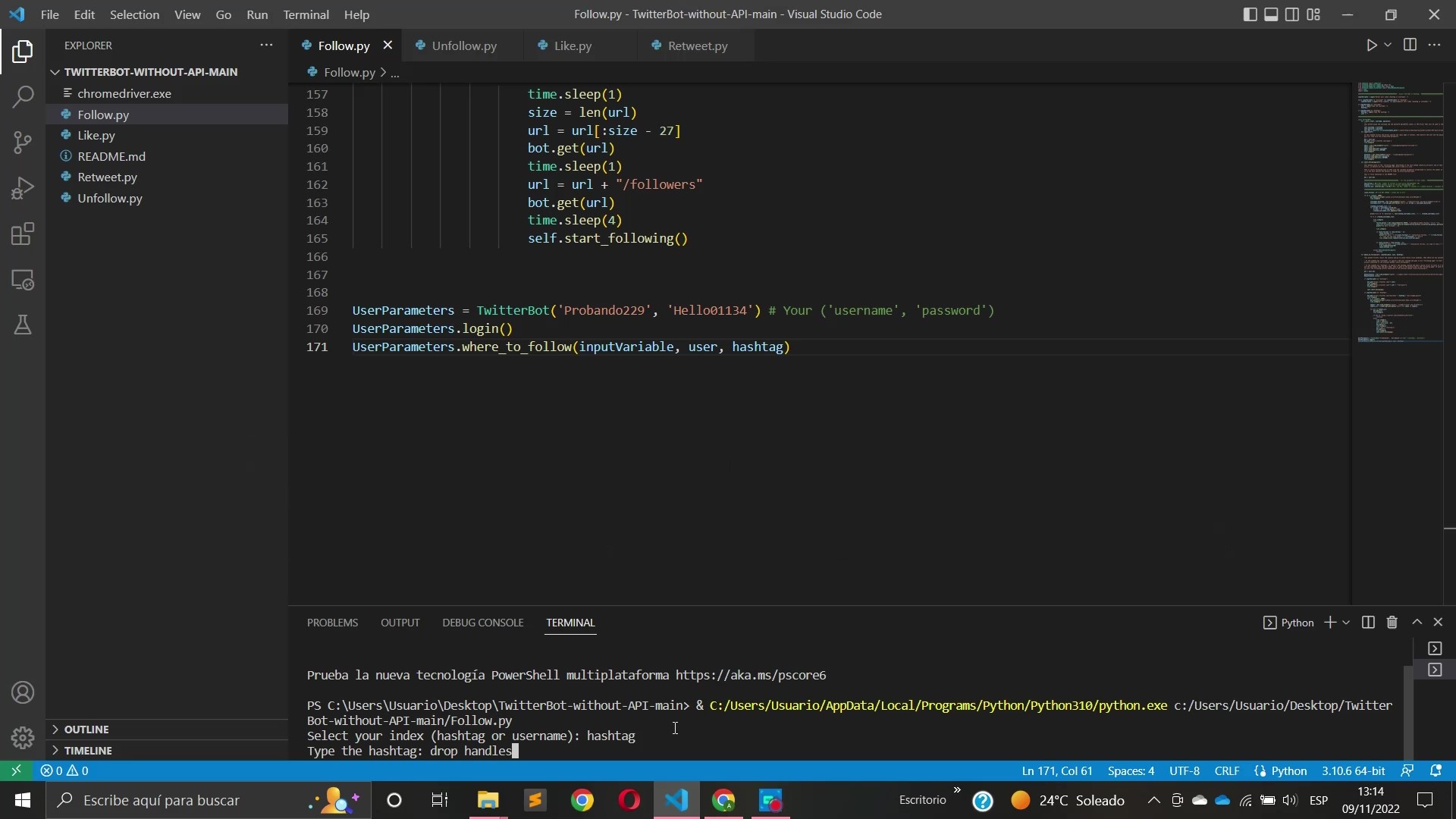
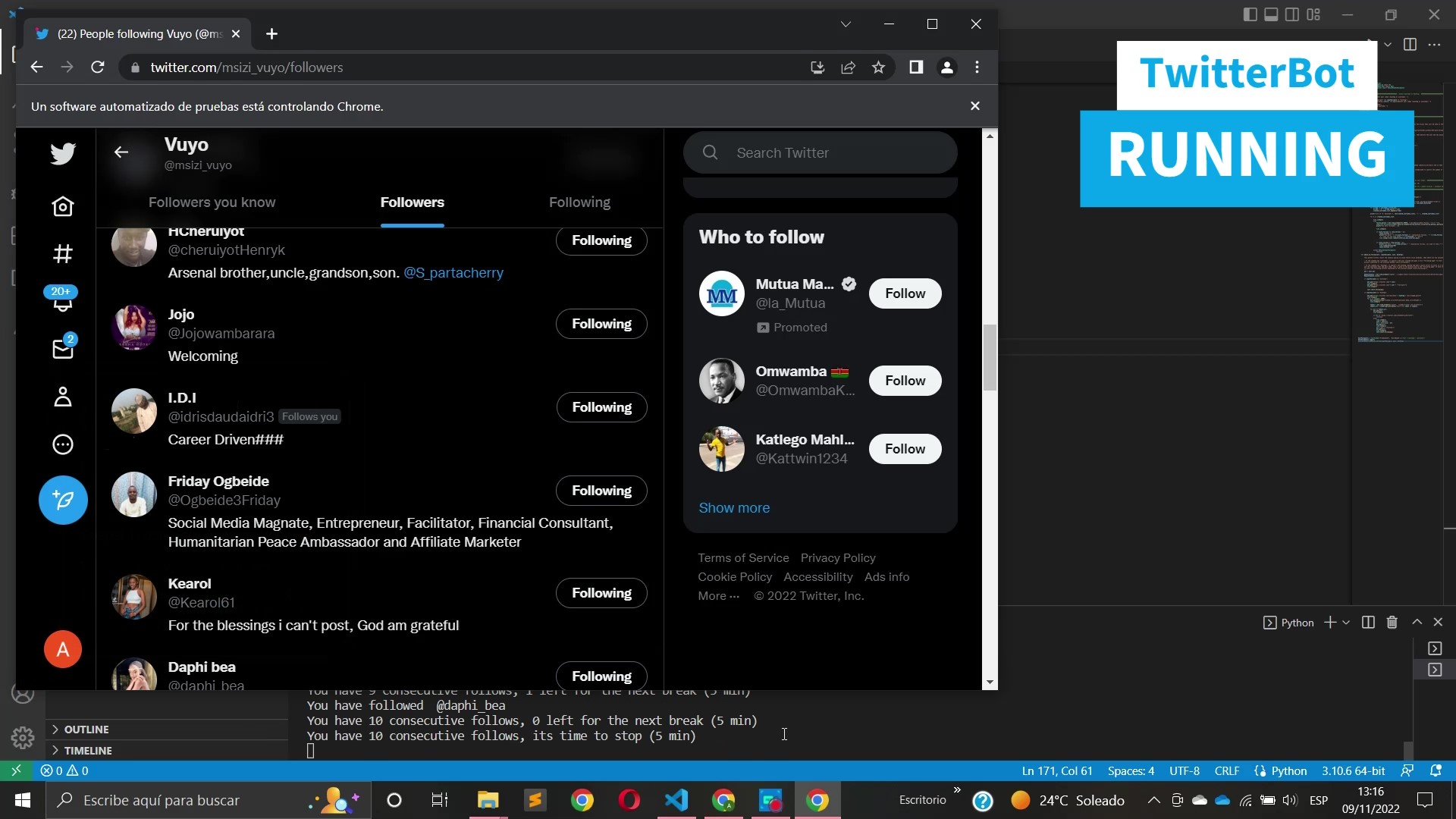
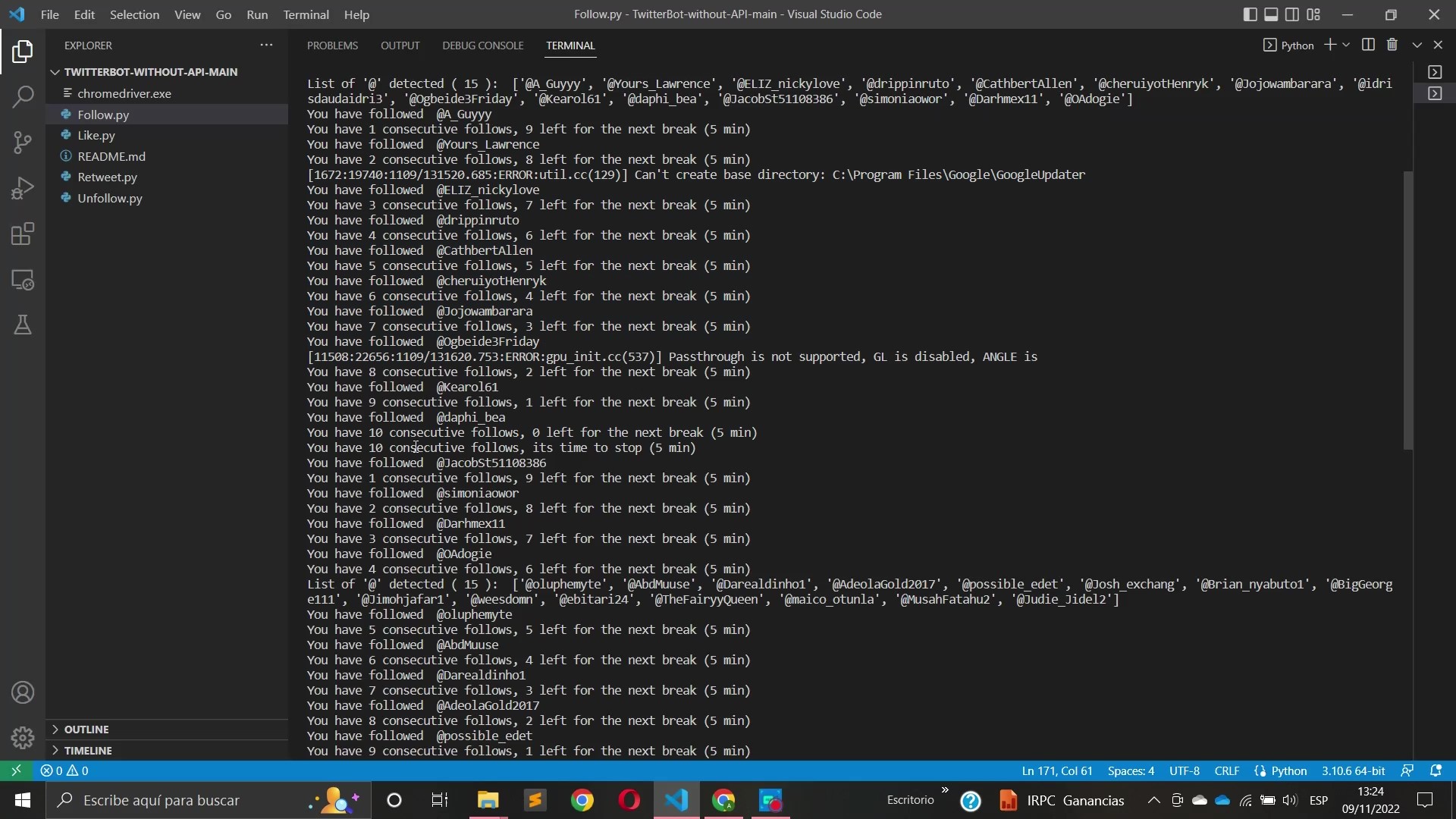
Pero volviendo al funcionamiento práctico del código que ya está creado y se puede descargar de forma totalmente gratuita en mi Github, el bot utiliza un driver de Google Chrome para dar follows/unfollows/likes/retweetsde manera totalmente automatizada y con una serie de cooldowns entre acciones y intervalos de tiempo randomizados que evaden los sistemas de baneo de Twitter.
Todos estos scripts tienen más o menos el mismo funcionamiento, como input puedes elegir entre un hashtag, y dentro de ese hashtag elegir entre los tweets más populares o los más recientes, o en su defecto puedes elegir un nombre de usuario como índice para ejecutar la acción. Por ejemplo si ejecutas el script «Like» y como índice le indicas que utilice los tweets más populares del hashtag «drop handles to gain followers» este bot empezará a dar likes indefinidamente a todos los tweets populares de ese hashtag y respetando los tiempos que evitan que el sistema de baneos de Twitter te detecte.
Además todo esto lo consigue sin utilizar la API de Twitter que facilitaría en gran medida el código pero que limita y rastrea en gran medida todas tus acciones.
Como ya hemos comentado antes, el funcionamiento de estos scripts depende de el código html de Twitter y por lo tanto pueden haber variaciones en ese código que creen incompatibilidades y fallos en nuestro bot por lo que es un proyecto que debe ir actualizándose constantemente en el tiempo.
Una de las funcionalidades que se van a añadir en el corto plazo al código abierto de Github es el almacenamiento de tweets con un funcionamiento muy similar al resto de algoritmos.
A partir de un índice introducido que puede ser o bien un hashtag, y dentro de ese hashtag la página de tweets «más populares» o la de «más recientes«, o bien un nombre de usuario, almacena en un archivo .txt los siguientes elementos:
El link del tweets
El contenido del tweet
El nombre de usuario y su arroba
El número de likes, retweets y citados del propio tweet .
Ya tengo el código creado y aparentemente sin errores por lo que simplemente falta limpiar el código y explicar el funcionamiento de cada método dentro del propio algoritmo.
Otra idea a largo plazo es crear una interfaz gráfica que enumere las acciones que está ejecutando el bot en tiempo real y que, en defintiva, haga mucho más interactivo el código para el público menos especializado.