Procesamiento de datos en streaming
Descripción del proyecto
En esta entrada, explicaré paso a paso cómo he creado una aplicación en Python extrae datos de una API y los inserta en tiempo real en Azure Event Hubs que a su vez sirven como input de un job de Azure Stream Analytics, donde podemos crear consultas SQL personalizadas que se almacenarán en un Data Lake Gen 2
Requisitos previos
- Tener cuenta con suscripción activa en Microsoft Azure para implementar los recursos.
- Instalar VS Code o cualquier otro editor de código para desarrollar y ejecutar la aplicación de Python.
- Instalar Python y las librerías necesarias para el funcionamiento de la aplicación.
Creación de los recursos en Azure
Antes de crear los recursos en Azure, es importante comprender la arquitectura propuesta por Microsoft en su documentación oficial para proyectos de análisis de datos en tiempo real. Esta arquitectura nos proporciona diversas posibilidades en cuanto a las herramientas que podemos utilizar.

En este caso, utilizaremos una aplicación en Python para extraer datos de una API y importarlos en Azure Event Hub como recurso de ingesta. Posteriormente, utilizaremos los jobs de Azure Stream Analytics para crear consultas SQL personalizadas sobre los datos que van llegando en streaming desde nuestro Event Hub. Estas consultas nos permitirán transformar los datos, si es necesario, para posteriormente guardarlos en nuestro Data Lake.
Como se muestra en la imagen, las consultas de Stream Analytics también se pueden conectar a otros recursos, como por ejemplo el puzle dedicado de Synapse o Power BI en Direct Query, para visualizar los datos en tiempo real, entre otros.
Una vez que tenemos claro cómo vamos a orquestar nuestro proyecto, procederemos a crear los recursos necesarios para implementar la arquitectura.
Creación del grupo de recursos
Comenzaremos creando un grupo de recursos llamado «RG-StreamingDemo». Este grupo nos servirá como directorio general del proyecto.

Creación del Event Hub Namespace
Dentro del grupo de recursos, procedemos a la creación de nuestro Event Hub Namespace, en mi caso lo llamaré «EHNdemo», y seleccionamos la región de Azure más cercana a nuestra ubicación
A continuación, configuramos el tier según nuestras necesidades. Dado que se trata de un proyecto de demostración, optaré por el tier más básico para reducir costos. Sin embargo, debemos tener en cuenta que esta opción no nos permitirá utilizar la función de captura de datos. Además, este tier eliminará permanentemente los datos del Event Hub después de 24 horas.
Las unidades de procesamiento limitan la cantidad de eventos que se pueden procesar y la tasa de rendimiento que pueden manejar los Event Hubs. Al aumentar el número de unidades de procesamiento, incrementaremos su rendimiento y su capacidad de procesamiento.
En mi caso, utilizaré una única unidad de procesamiento, lo que significa que mis Event Hubs podrán procesar un máximo de 1 megabyte por segundo o 1000 eventos por segundo, lo que ocurra primero. Si superáramos este límite, recibiríamos una serie de «Exception error» durante el desarrollo del programa.

A continuación, en el menú de la izquierda, encontraremos la opción de «Event Hub». Al hacer click en ella, podremos crear nuestros Event Hubs. Para este proyecto sólo necesitaré un Event Hub que será el encargado de recibir los datos que enviaré desde el script de Python.
El número de particiones determina el rendimiento, la escalabilidad y la capacidad de procesamiento del Event Hub. Cada partición tiene su propia secuencia de eventos y puede recibir, almacenar y enviar eventos de forma paralela.
Para mi Event Hub, al cual llamaré “pythondata”, elegiré el número mínimo de particiones, que es 2, y el tiempo mínimo de retención de datos, que es de 1 hora.
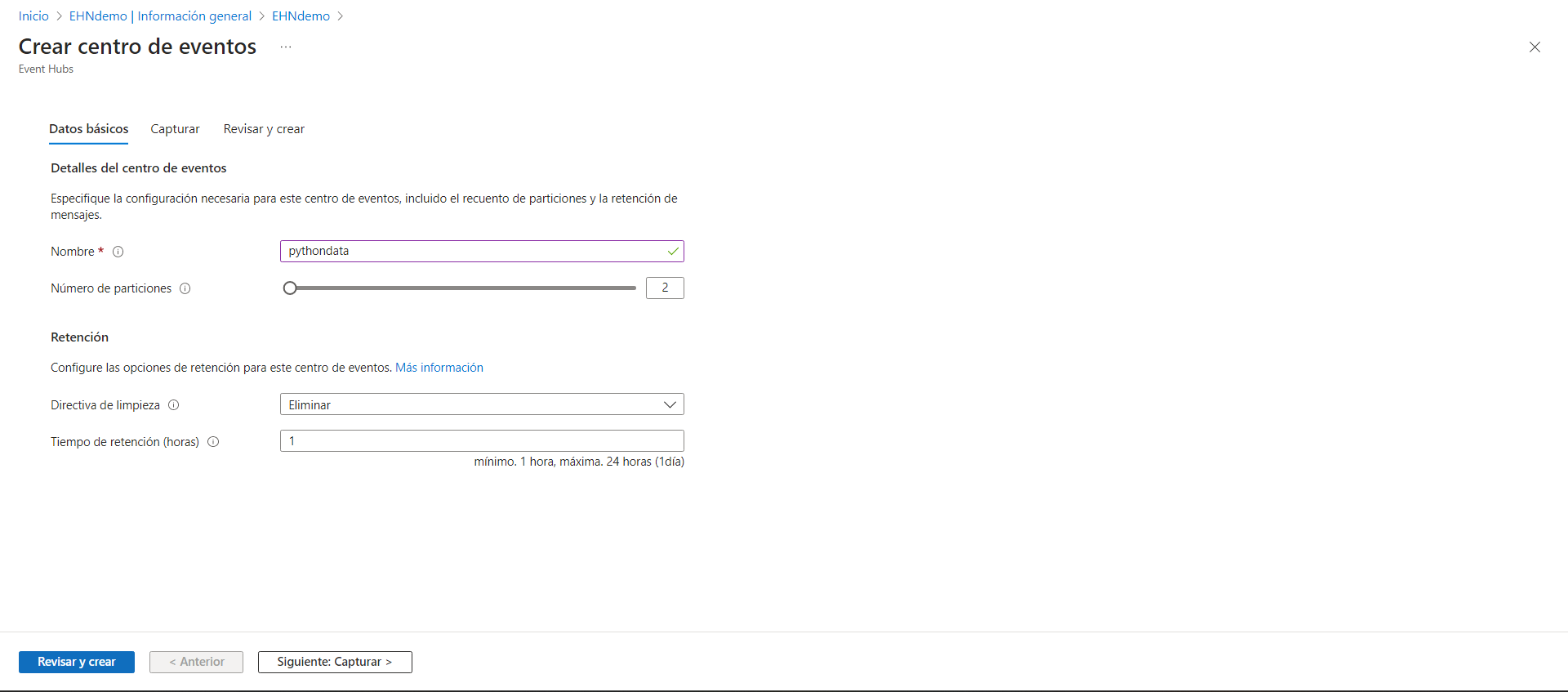
En el siguiente apartado podemos observar que, como mencionamos anteriormente, la opción de captura de datos no está disponible en el tier básico del Namespace. Si estuviéramos utilizando un tier superior y quisiéramos activar esta funcionalidad, deberíamos configurar un recurso de almacenamiento, como por ejemplo una cuenta de almacenamiento, para almacenar los datos a medida que van llegando.
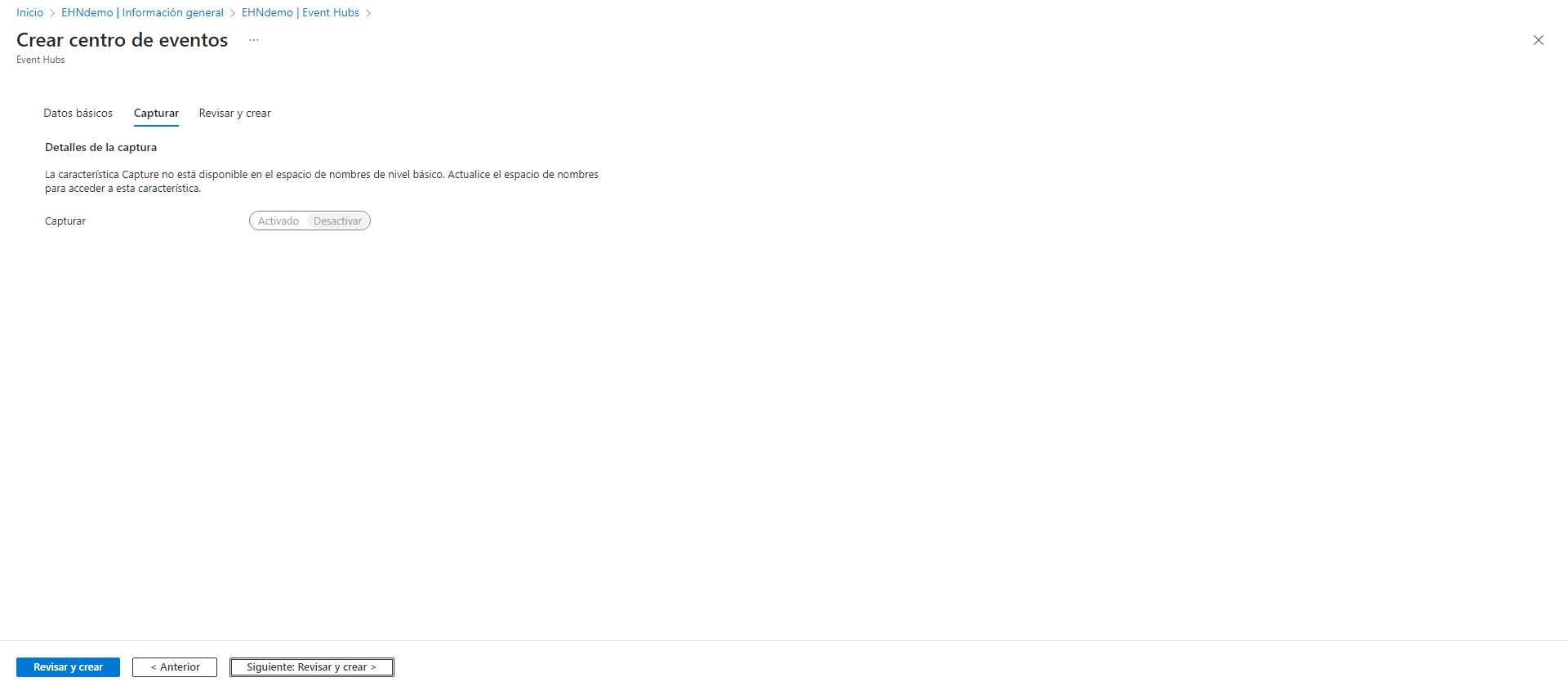
Creación del Azure Stream Analytics
Al igual que con el EHN, configuramos la suscripción, el grupo de recursos y el nombre del recurso pero aquí debemos tener en cuenta que la región que elijamos debe ser la misma que la que hemos elegido previamente en el Event Hub Namespace, de no ser así el job de Stream Anlaytics no podría recoger los datos de los eventos.
Al igual que en los recursos anteriores, hemos mencionado las particiones y las unidades de procesamiento, Stream Analytics tiene sus propias unidades de streaming. A medida que incrementamos estas unidades, aumentará la capacidad de procesamiento y también los costos del recurso. En mi caso, seguiré eligiendo el mínimo de unidades de streaming, ya que las necesidades de mi proyecto son básicas.
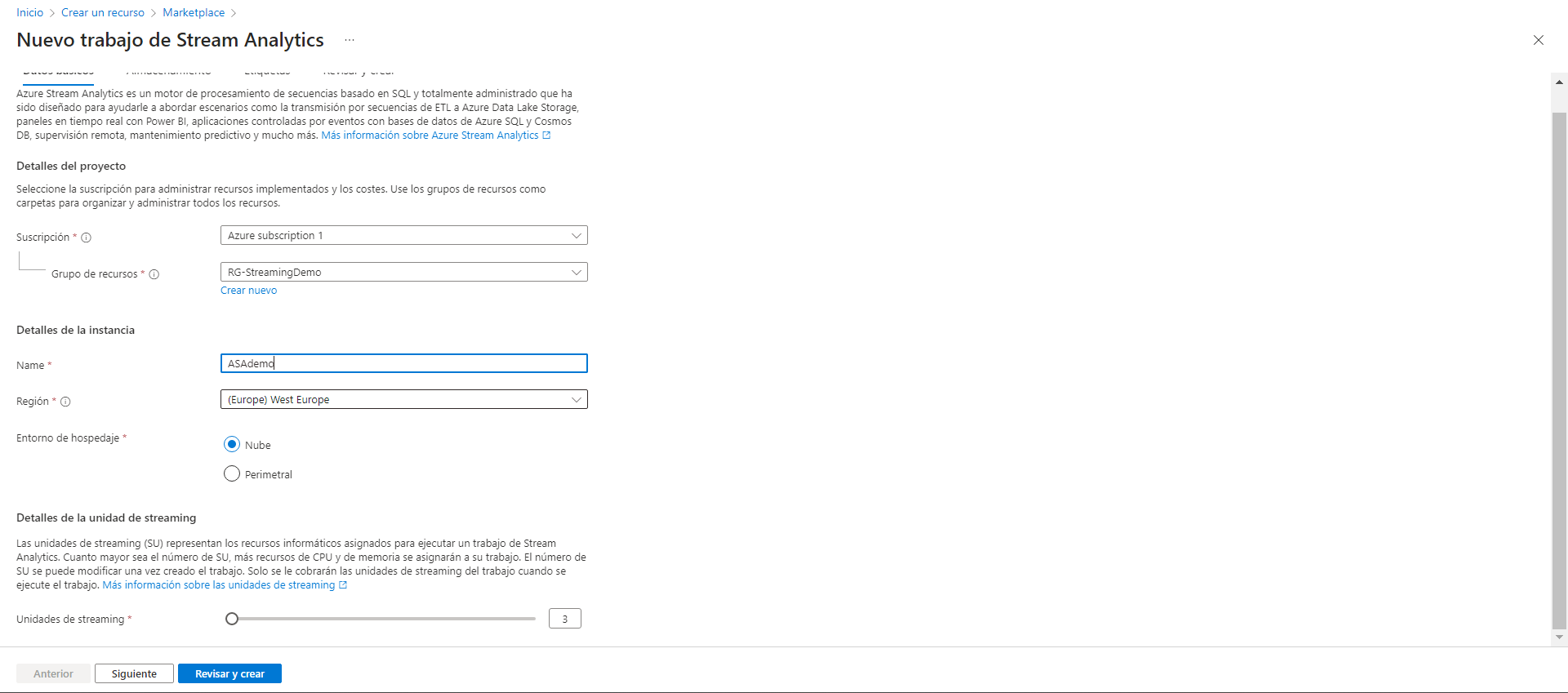
Una vez creado el recurso, si nos dirigimos a la sección de consultas, podemos escribir selects como lo haríamos en cualquier herramienta SQL para enfocar nuestras consultas de forma totalmente personalizada.
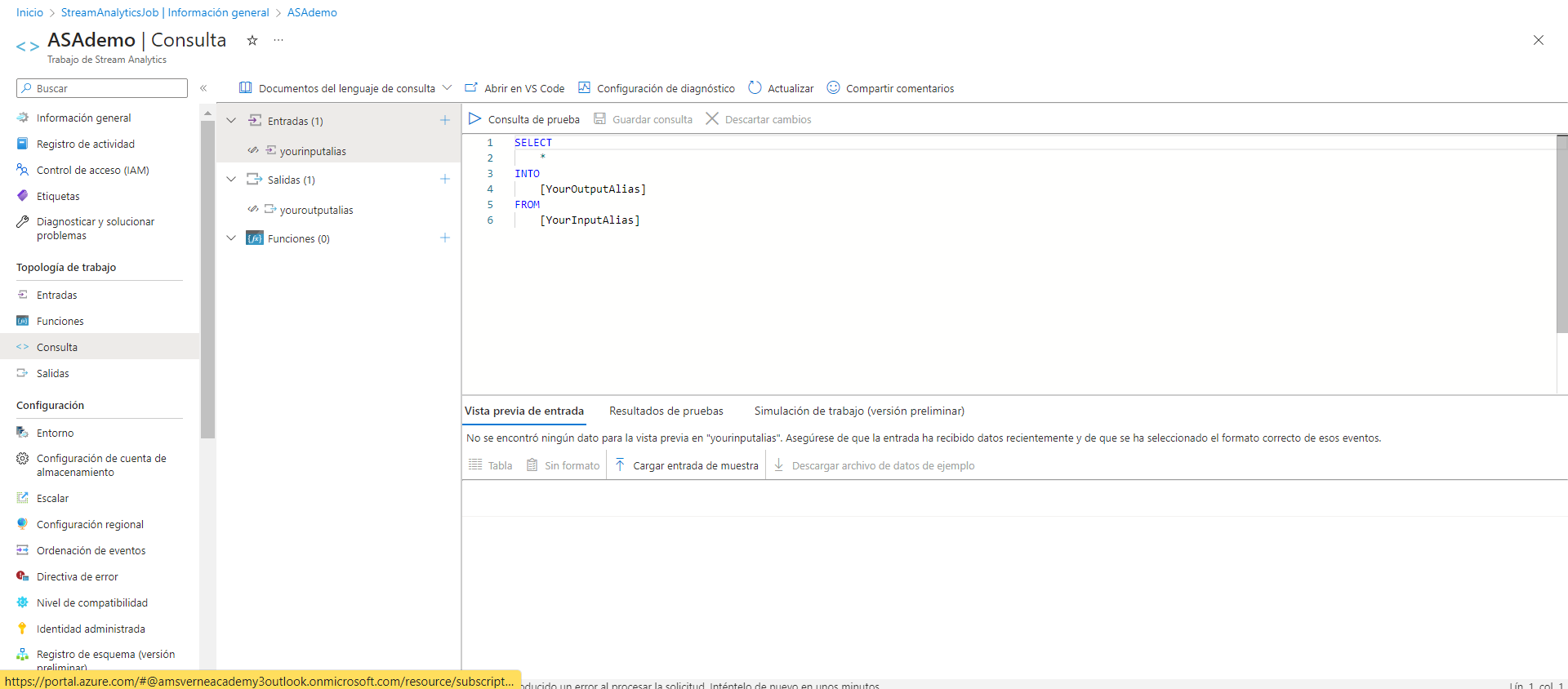
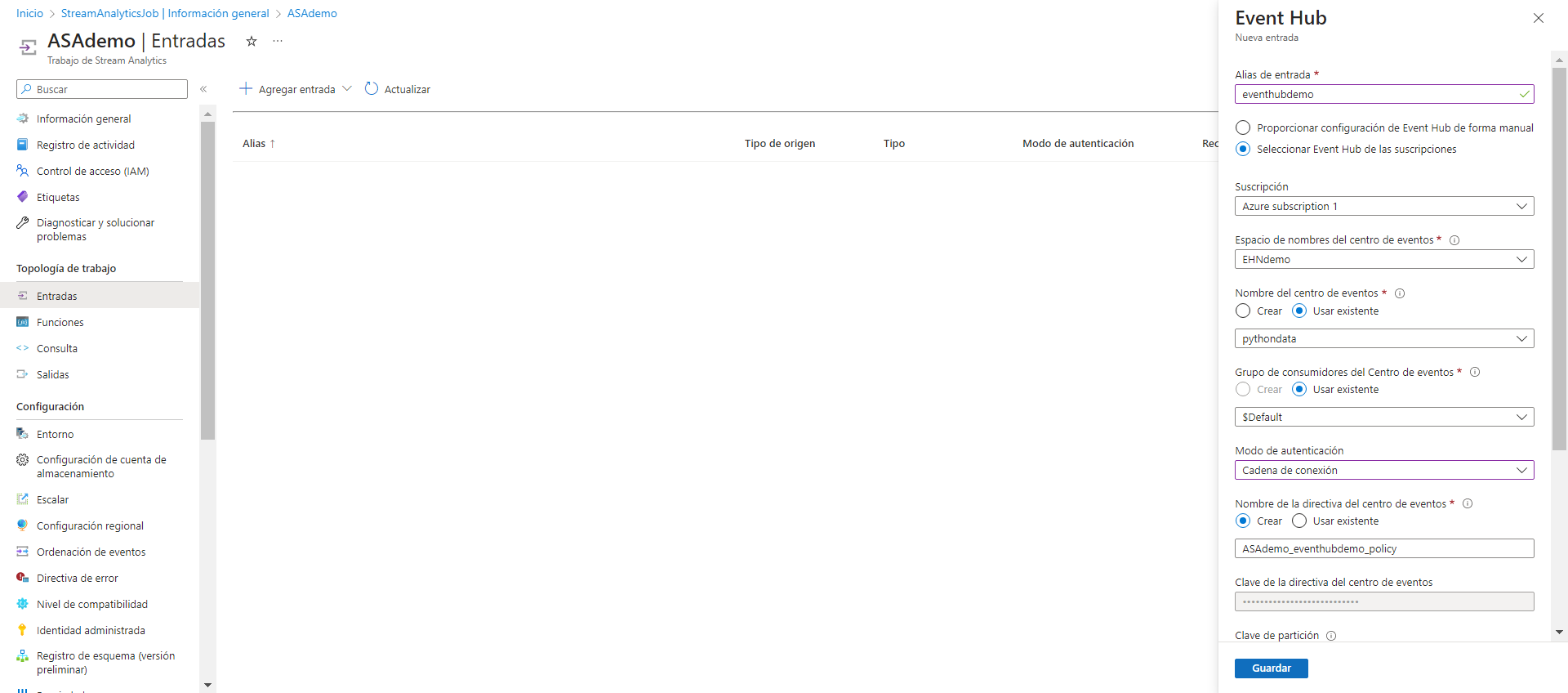
Por último, para consultar los datos del Event Hub, debemos configurarlo como entrada (input) en el apartado de entradas de Stream Analytics. Simplemente seleccionaremos el Event Hub que ya hemos creado y cambiaremos únicamente la opción de autenticación a «Cadena de conexión».
Desarrollo de la aplicación
Ya con todos los recursos necesarios creados en el portal de Azure, simplemente necesitamos conectarnos a una fuente de datos que en mi caso será un script de Python que, a través de la API “yahoo_fin”, extrae en tiempo real los datos bursátiles de Microsoft y los envia al Event Hub para que sean analizados, también en tiempo real, a través de consultas en Stream Analytics.
Para resumir lo que hace este script lo dividiré en 3 secciones:
Importar librerías
Las librerías en Python son conjuntos de métodos y código reciclado que hacen la vida mucho más sencilla a los usuarios menos especializados. En este caso utilizaré estas librerías:
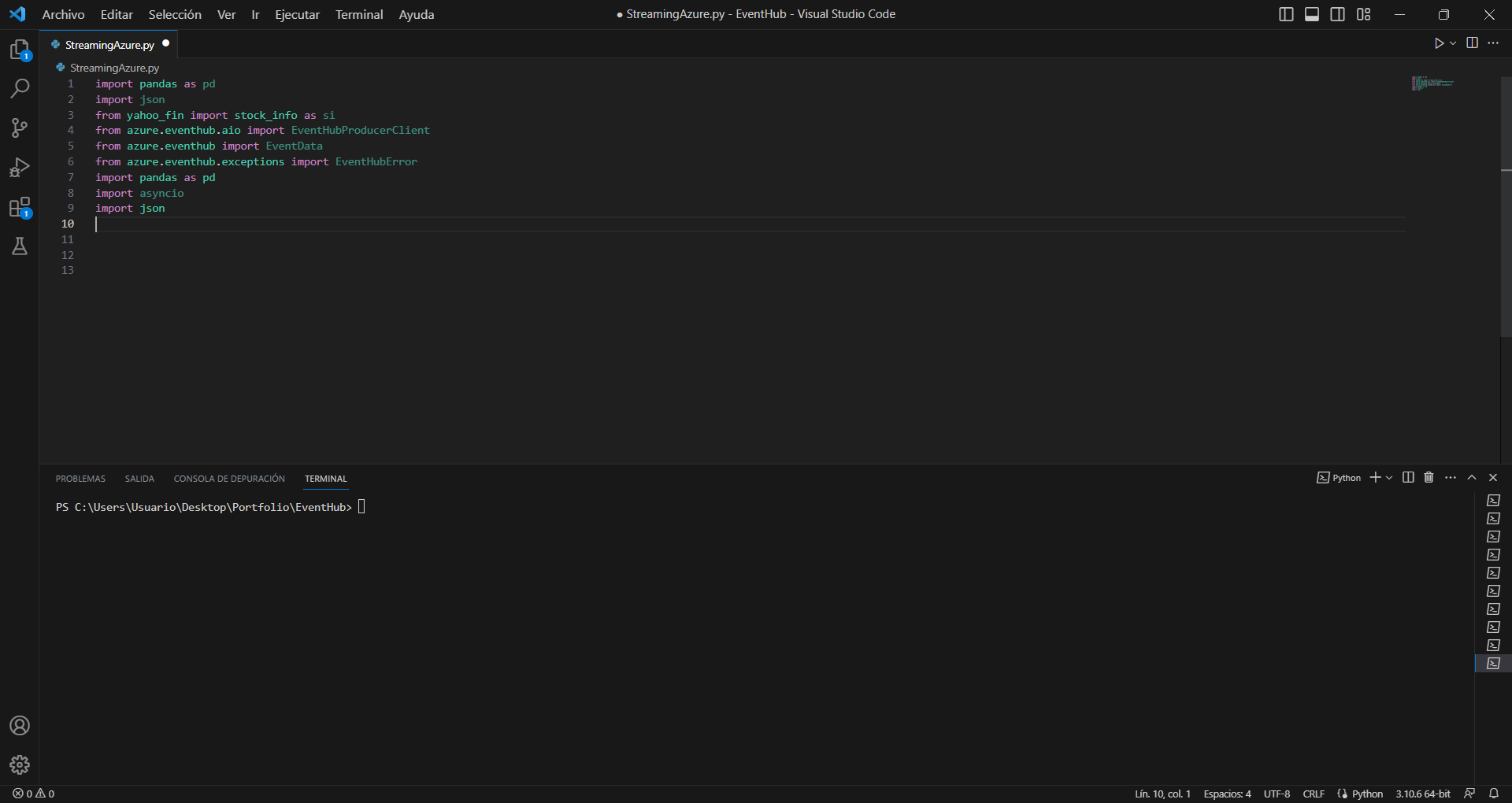
En resumidas cuentas yahoo_fin es la API que utilizaremos para extraer la información en tiempo real de los datos bursátiles de Microsoft, azure.eventhub nos permite conectarnos al Event Hub, enviarle los datos y tratar con las excepciones, pandas nos permite utilizar dataframes para cargar los datos extraídos de la API y transformarlos de forma rápida e intuitiva, asyncio se ocupa principalmente de la programación asíncrona y nos servirá de gran ayuda para ir enviando continuamente los datos al Event Hub y por último json y datetime nos servirán para tipar correctamente los datos
Crear la función para extraer datos
Esta función recibe como input el ticker de la empresa de la cual queremos extraer sus datos bursátiles, en mi caso Microsoft (msft), y devuelve como output un diccionario con los datos que le indicamos.

Analizando un poco más en profundidad el código, el método get_quote_data() es el que ofrece los datos en crudo de la API. Este método entrega un extenso diccionario con información de todo tipo.
Para seleccionar, transformar y tipar los datos para su posterior análisis, cargo el diccionario en un dataframe de pandas únicamente con las columnas que me interesan.
A la columna “regularMarketTime” que en crudo da un valor entero de muchos números le indico que ofrezca la solución como fecha y posteriormente la tipo como string para evitar futuros problemas de incompatibilidad con el formato fecha.
La columna “averageAnalystRating” la divido por el delimitador “-“, creo la columna “AnalystRating” con la valoración numérica (Izquierda del delimitador) y la columna “AnalystRecommendation” con el texto (Derecha del delimitador). Finalmente elimino la columna original que ya no me sirve de nada
Además creo a la columna “MarketCapInTrill” redondeando la columna “marketCap” a trillones y añadiéndole los símbolos “€” y “MM”

Copiar la función de la documentación oficial de Microsoft
Por último, para enviar los datos a los Event Hubs utilizaré una función que tiene Microsoft subida en su documentación oficial que, en resumidas cuentas, se conecta al Event Hub a través de su cadena de conexión y envía en batch el input en questión.

Esta función yo la he iterado en un bucle infinito con un cooldown de 5 segundos indicándole además de los parámetros de conexión propios del Event Hub, el output de la función extraer_datos() como input del Event Hub.

Por lo tanto cada 5 segundos mi aplicación extrae los datos de la API, los tranformay los enviará a mi Event Hub indefinidamente.
Consulta y almacenamiento en Azure
Teniendo los recursos en el portal de Azure creados y los eventos configurados para empezar el proceso de análisis en tiempo real, estamos listos para empezar a realizar nuestras consultas.
En mi caso ejecuto el programa de Python y tras comprobar que todo funciona correctamente y sin errores puedo ver en las gráficas del Event Hub como empiezan a llegar los eventos.
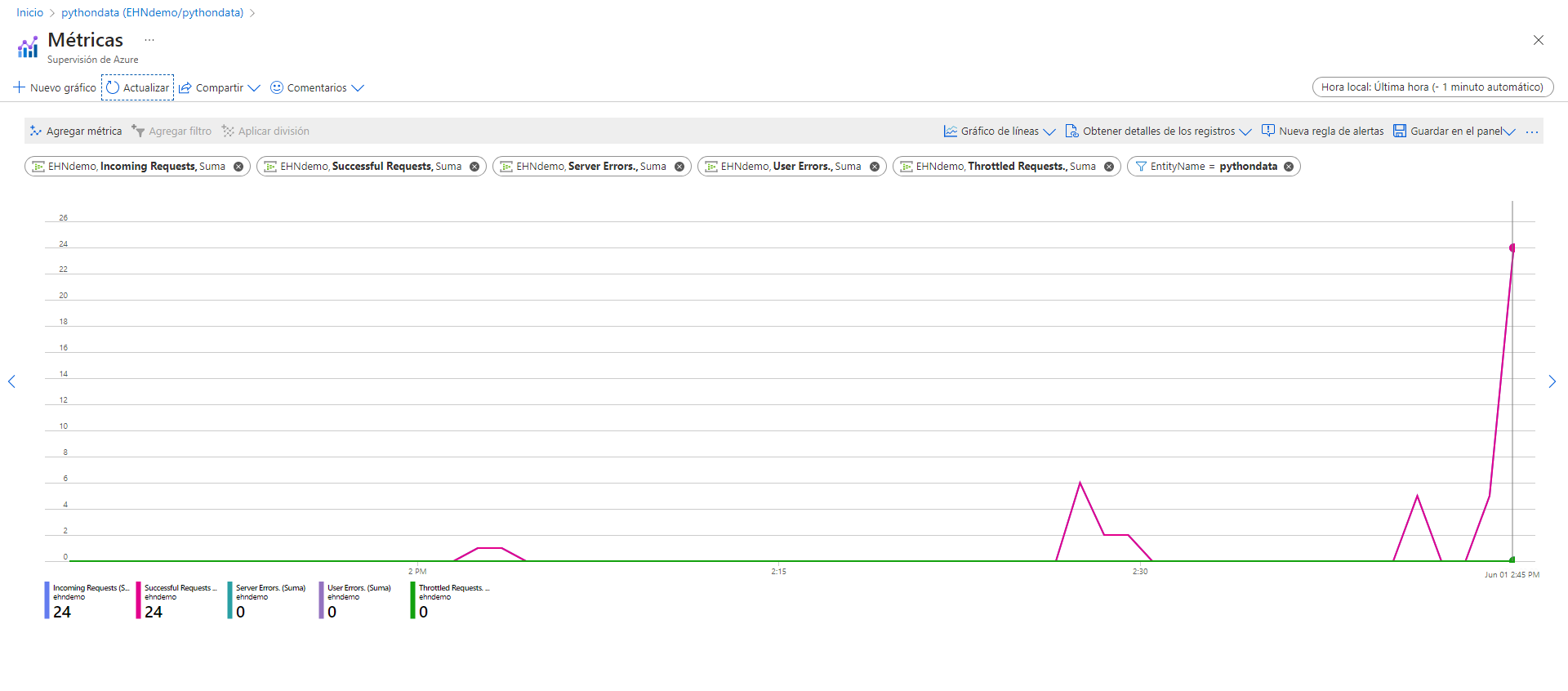
Tras comprobar que efectivamente los Eventos están llegando con la frecuencia esperada podemos empezar a consultar los datos en el Stream Analytics, simplemente necesitamos configurar el input en la consulta SQL para ver los resultados.
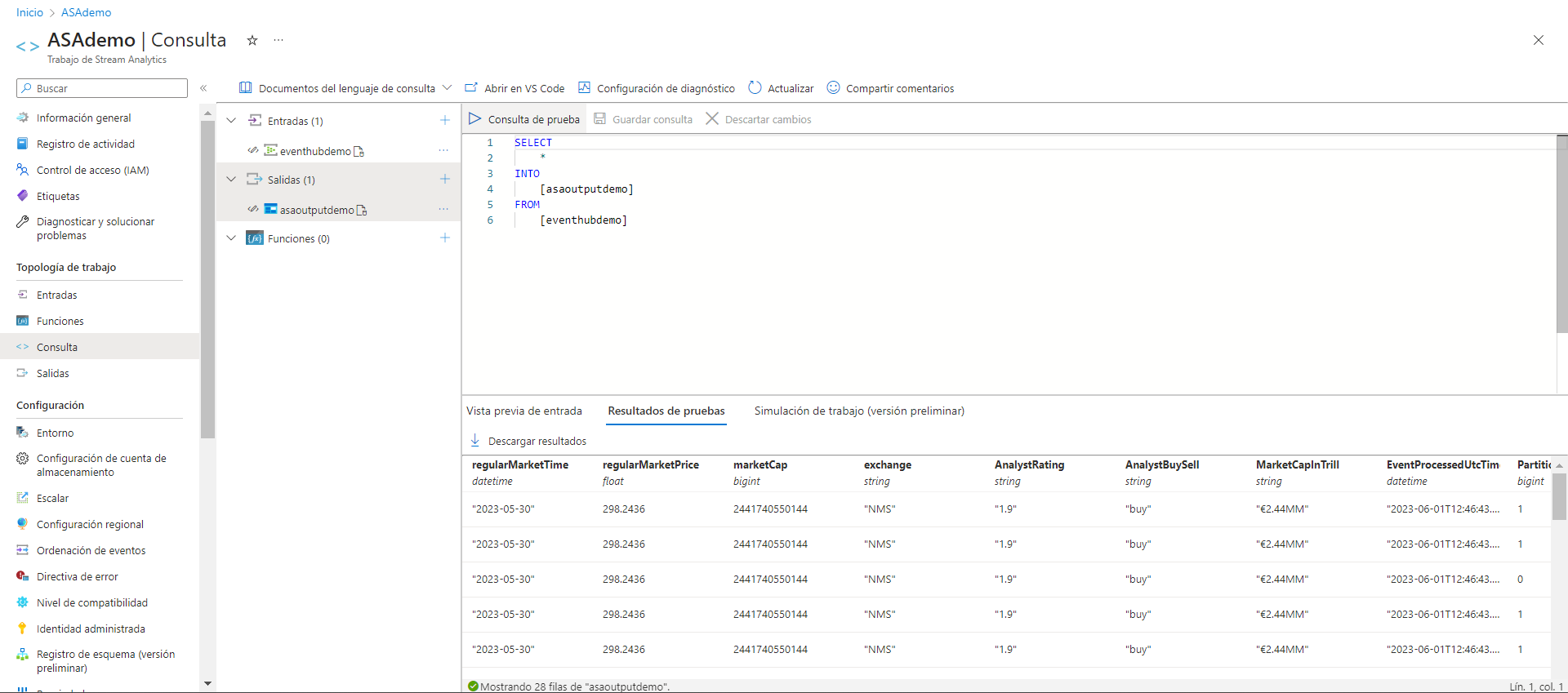
Como ya hemos comentado antes, en este punto podemos modificar las consultas a medida para obtener diferentes resultados. Además podemos especificar un output o bien para almacenar los datos que van llegando, o bien para visualizarlos en tiempo real por ejemplo en Power BI.
En mi caso, configuro como output una cuenta de almacenamiento que ya tenía creada y le indico la ruta en la que quiero almacenar los archivos que van llegando.
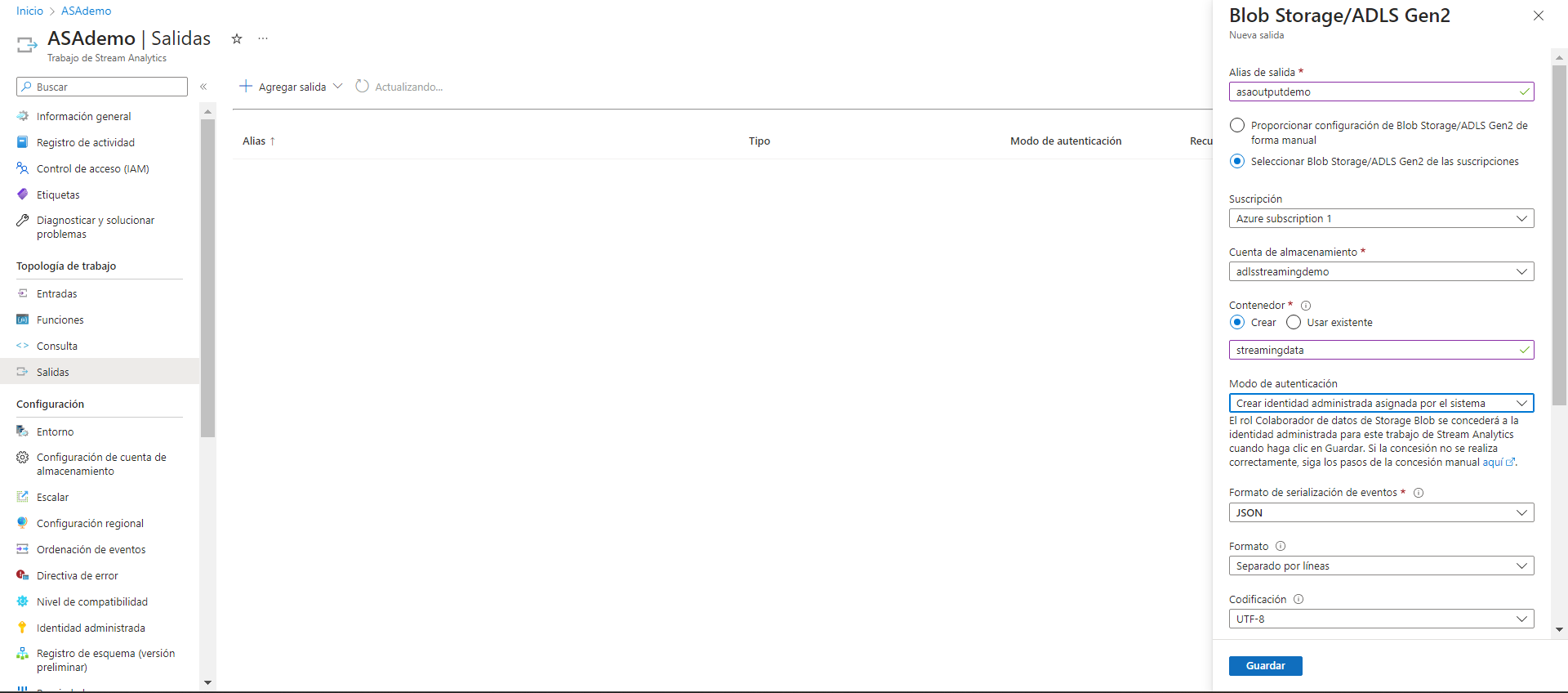
Teniendo el input y el output configurados en la consulta, simplemente nos falta ejecutar el job de Stream Analytics y comprobar que todo está funcionando como debería.
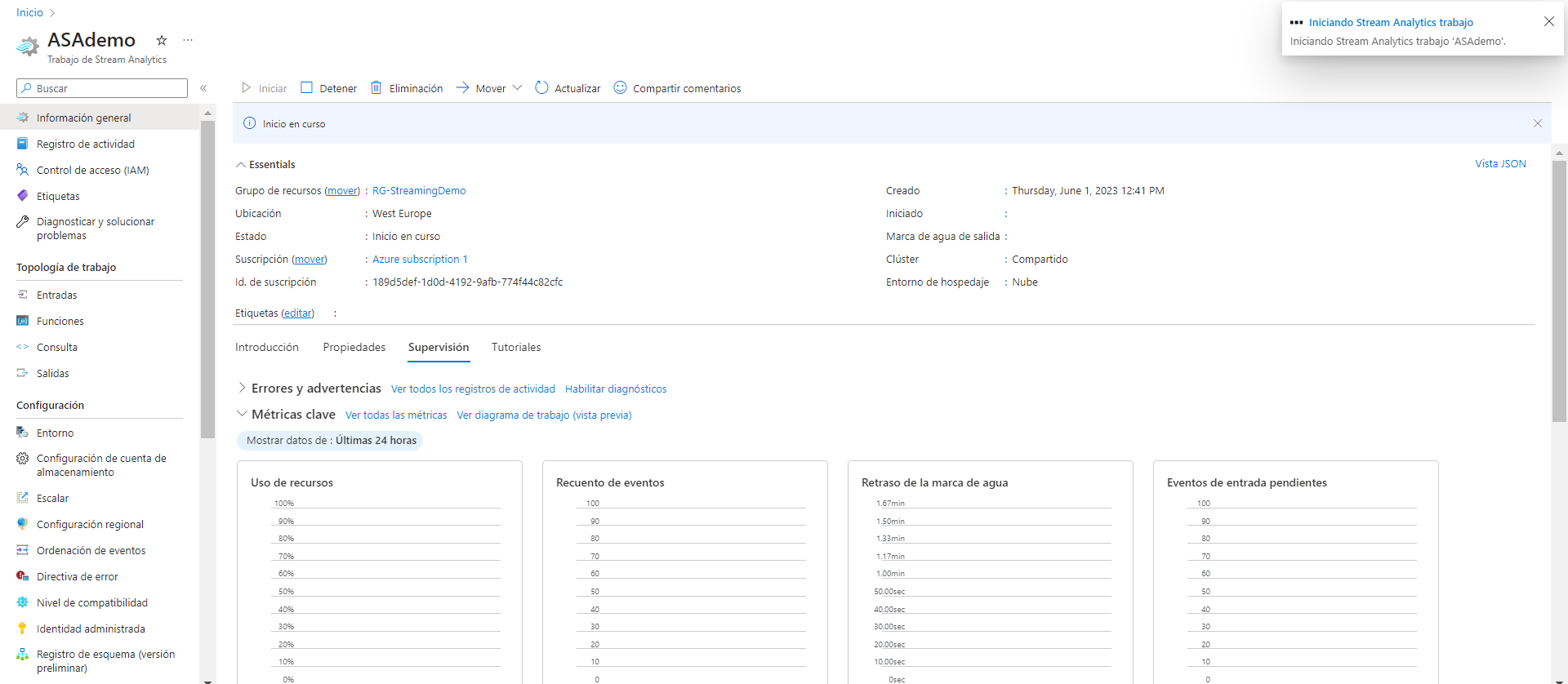
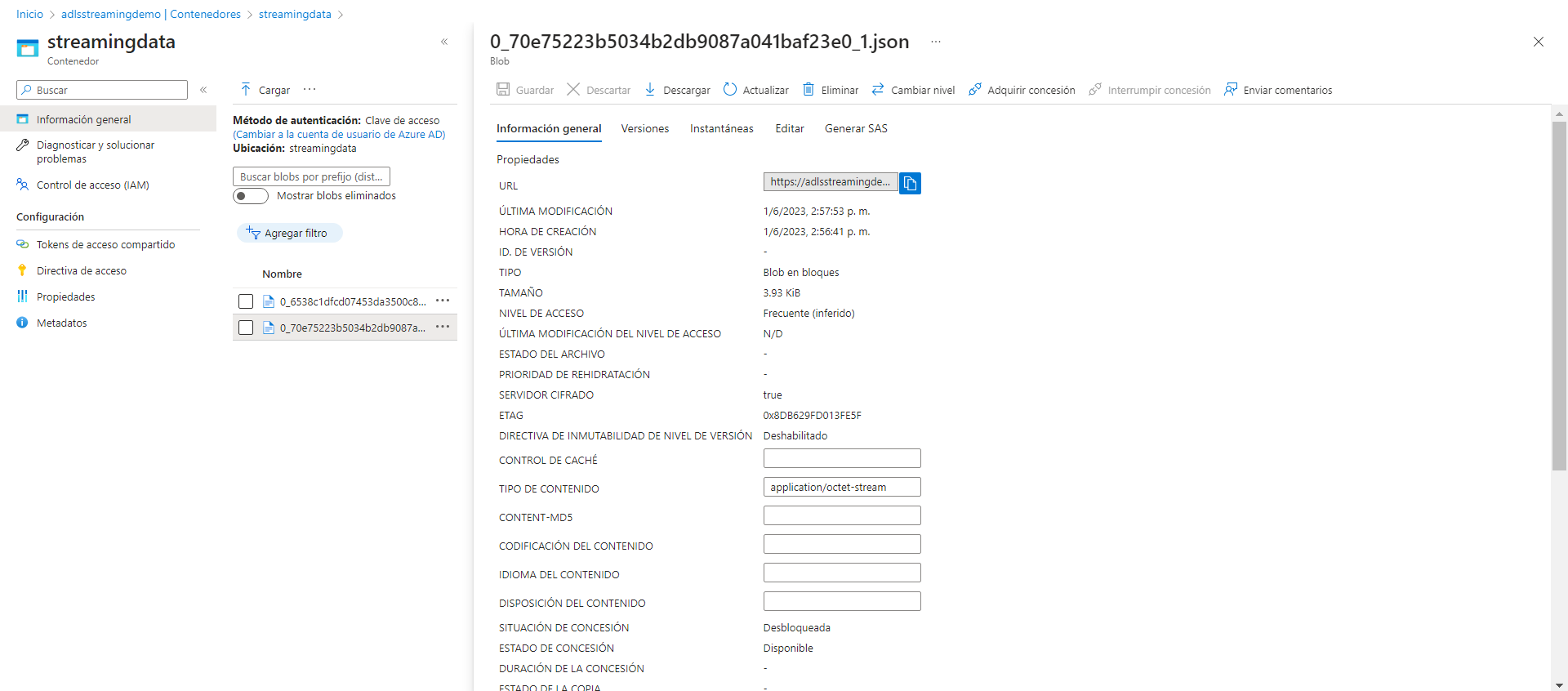
A partir de aquí cada usuario define cuánto tiempo necesita tener el job activo, en mi caso tras comprobar que efectivamente los json con los datos bursátiles de Microsoft están llegando correctamente al Data Lake, detengo la ejecución de Stream Analytics y del script de Python y concluyo aquí mi proyecto demo de análisis de datos en streaming.
Conclusión
En conclusión, en este proyecto hemos visto cómo desarrollar desde 0 una aplicación en Python que extrae los datos de una API pública, los transforma de forma personalizada, y los envía indefinidamente sin errores y pérdida de información al portal de Azure.
Para recibir, analizar y almacenar estos datos en tiempo real hemos creado y configurado, a medida de nuestras necesidades y minimizando costes, un Event Hub Namespace con su propio receptor de eventos y un job de Stream Analytics con un input y un output asignados a sus consultas.


