Arquitectura Lakehouse
Esta entrada tiene como objetivo proporcionar una descripción detallada de mi TFM del Máster de Analítica Avanzada en Tecnologías Microsoft, en el cual abordé la migración de los datos y la reestructuración del ETL de una empresa dividida en tres delegaciones (España, Francia y Portugal) hacia una plataforma centralizada en Microsoft Azure.
La solución propuesta está basada en una arquitectura Lakehouse y se centra inicialmente en la creación de un Datamart de ventas como prueba de concepto, con la visión de una migración completa de la empresa en el medio/largo plazo.
Situación inicial
Esta entrada tiene como objetivo proporcionar una descripción detallada de mi TFM del Máster de Analítica Avanzada en Tecnologías Microsoft, en el cual abordé la migración de los datos y la reestructuración del ETL de una empresa dividida en tres delegaciones (España, Francia y Portugal) hacia una plataforma centralizada en Microsoft Azure.
La solución propuesta está basada en una arquitectura Lakehouse y se centra inicialmente en la creación de un Datamart de ventas como prueba de concepto, con la visión de una migración completa de la empresa en el medio/largo plazo.
La empresa NWS, que vende todo tipo de productos elaborados con tejidos sintéticos en 3 países distintos (España, Francia y Portugal), se pone en contacto conmigo para actualizar su actual arquitectura de datos y migrar toda su plataforma a la nube de Azure. Actualmente la empresa almacena la información de cada una de las 3 delegaciones de forma independiente, es decir, cada delegación tiene su propia base de datos en SQL Server nutrida por sus propios ERP y CRM.
Además, cada delegación analiza sus datos en plataformas de visualización independientes. Los usuarios crean sus informes en Excel o Power BI conectándose directamente a algunas tablas comunes de la empresa en excel o csv y al sistema transaccional mediante una serie de vistas entrelazadas y poco eficientes con el riesgo de colapso y, por lo tanto, pérdida de datos que esto puede suponer para la empresa.
El hecho de que cada delegación almacene y analice los datos de forma independiente, con su propio idioma y metodología, hace que sea prácticamente imposible realizar un análisis global de la empresa con una única versión de la información.
Requisitos del cliente
Tras una serie de reuniones con el cliente y ya con los principales problemas de la actual arquitectura identificados, marcamos una serie de requisitos indispensables para la nueva arquitectura.
- Migración a Azure, no tiene sentido mantener 3 servidores independientes con una escalabilidad y seguridad limitadas.
- Repositorio de datos centralizado, escalable, seguro que genere una única versión de la verdad con la inormación global de la empresa.
- Unificar la plataforma de informes para que todos los usuarios de las distintas delegaciones accedan a los mismos informes y puedan ver, o bien la información de toda la empresa, o bien la información de su propia delegación en función al rol de seguridad que se les haya asignado.
- Utilizar las herramientas adecuadas para mantener el coste de implantación y posterior mantenimiento lo más bajo posible
Debemos tener en cuenta también a la hora de desarrollar la nueva arquitectura que, aunque el proyecto está basado únicamente en el datamart de ventas como prueba de concepto, la arquitectura debe contemplar la migración de toda la empresa con una previsión del volúmen de datos de +100GB y en constante crecimiento.
Estos requisitos establecidos servirán como pilares fundamentales para guiar el desarrollo de la nueva arquitectura, asegurando que se cumplan las expectativas del cliente y se prepare el camino para una migración exitosa a gran escala en el futuro.
Solución propuesta
En respuesta a los requisitos del cliente y con el objetivo de abordar los problemas identificados en la arquitectura existente, se ha diseñado una solución integral que abarca desde la ingesta de los datos hasta la creación y administración de la plataforma de visualización y sus informes.
La solución propuesta se basa en los principios de una arquitectura Lakehouse, aprovechando las capacidades de Microsoft Azure para ofrecer escalabilidad, seguridad y eficiencia en el procesamiento de datos para su posterior análisis en Power BI.

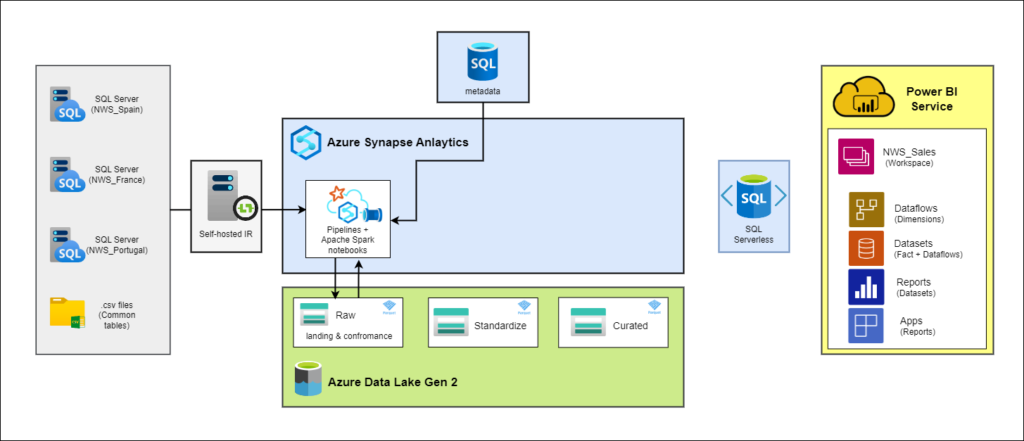
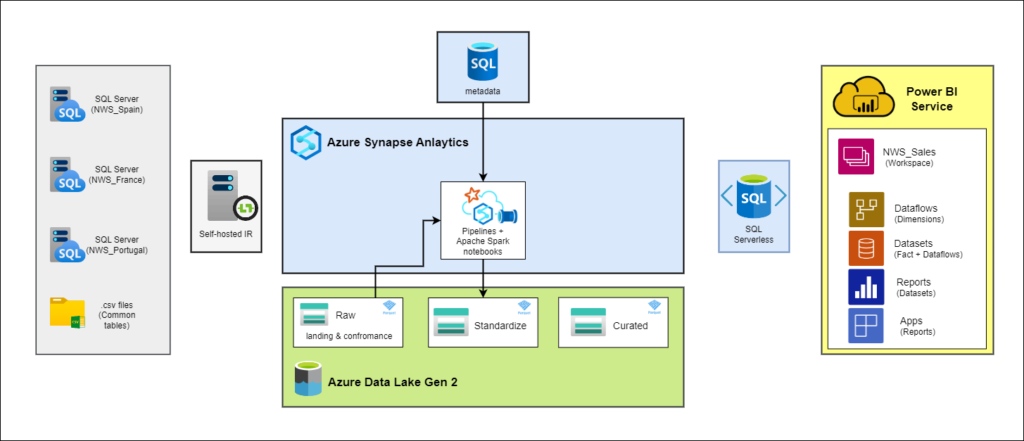
Ingesta
La ingesta de datos es una fase crítica en la implementación de la solución propuesta. Esta etapa implica la transferencia de datos desde las fuentes existentes, que están distribuidas en las tres delegaciones (España, Francia y Portugal), hacia el entorno centralizado en Azure.
En este caso, las fuentes de datos incluyen tanto las bases de datos de SQL Server que están actualmente en uso en cada una de las delegaciones como la carpeta compartida de los datos comunes de la empresa con algunas tablas en csv o excel. Cada una de estas fuentes contiene datos relacionados con las operaciones, ventas, clientes y otros aspectos comerciales.
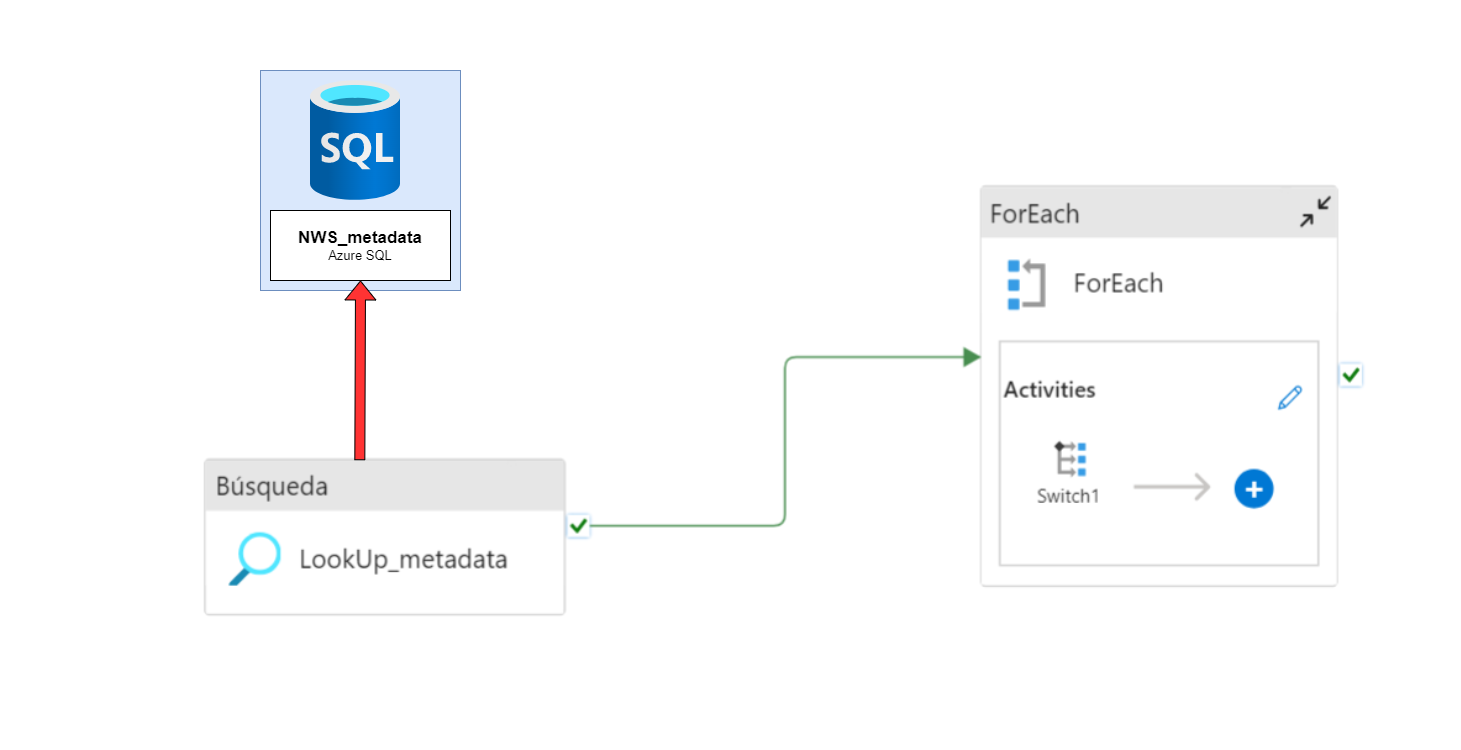
En cuanto a las herramientas utilizadas en esta fase del ETL, para la transferencia de datos desde los distintos orígenes on-premise a Azure, se utilizarán las canalizaciones de Azure Synapse Analytics, conectadas a las fuentes de datos mediante Self-hosted Integration Runtimes, orquestadas por una base de datos de Azure SQL.
En resumen, las canalizaciones consultan la información de las tablas y columnas (nombre, orígenes, destinos, tipos de carga…) en la base de metadatos de Azure SQL mediante la actividad de LookUp para nutrir con esa información la actividad de Copy Data, que realiza una ingesta «pull» o «pull-based» ya que está extrayendo datos de l origen y cargándolos en el destino, en lugar de esperar a que la fuente de origen envíe los datos activamente al sistema.
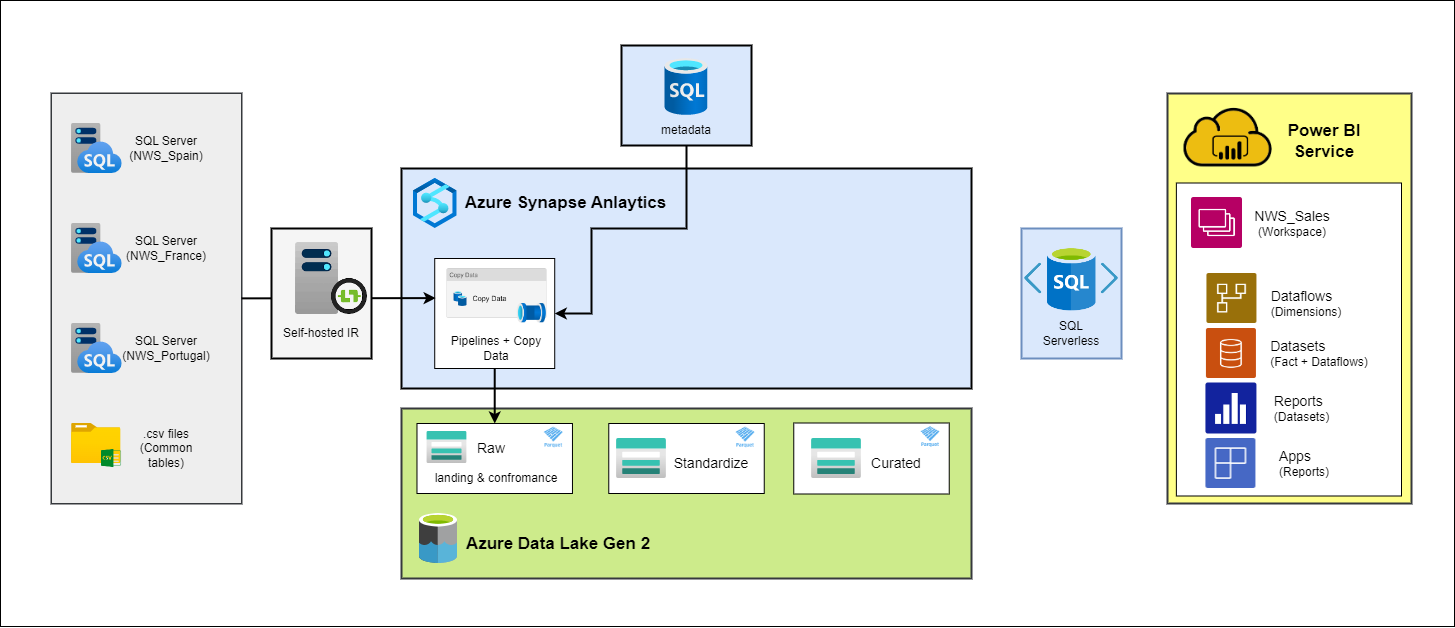
Estructura del Data Lake
Sabiendo ya cuáles son las fuentes de la ingesta y cómo las canalizaciones extraen la infromación de los origenes, sólo nos queda entender cómo se organizan y se almacenan los datos en el Data Lake de destino. Esta estructura se compone de tres capas distintas en función de la maduración de los datos: raw, std y curated. A continuación, se detallan las características y el propósito de cada una de estas capas:

raw
La capa raw es la primera parada de los datos después de la ingesta. Aquí se almacenan los datos en dos subcapas: landing y conformance.
raw/landing(Datos en su forma original): En esta subcapa, los datos se mantienen en sus formatos originales, sin modificaciones, lo que facilita la recuperación de datos históricos. Al no aplicar ninguna transformación los datos pueden estar potencialmente duplicados.raw/conformance(Datos en Parquet, deduplicados): En esta subcapa, los datos ya se almacenan en formato Parquet para optimizar el rendimiento y se eliminan duplicados para garantizar la calidad de los datos.
En ambas subcapas, los datos se organizan por delegación, lo que significa que se mantienen separados según la ubicación geográfica:
- NWS_Spain, para los datos originarios de la delegación de España
- NWS_France, para los originarios de Francia
- NWS_Portugal, para los originarios de Portugal
- Common, para los datos originarios de la carpeta compartida entre las 3 delegaciones
Esto permite rastrear la procedencia de los datos.
std
La capa std es donde los datos se transforman y se estandarizan. Aquí se producen las siguientes transformaciones:
- Centralización de los datos, es decir, la unión vertical de tablas comunes entre las distintas delegaciones. Por ejemplo, TCLIENTES (España), Clients (Francia) y CLIENTES (Portugal) forman la tabla Clients (Nombre de tabla, columnas y documentación en inglés, idioma común)
- Desnormalización de las tablas, unión horizontal de las distintas entidades que forman una misma tabla en el modelo analítico. Por ejemplo, SalesHeader + SalesLine forman la tabla de hechos Sales
- Se le añade la propiedad SCD tipo 2 (Slowly Changing Dimension) a algunas dimensiones.
La centralización de los datos aporta una visión global de la empresa en el análisis, la desnormalización de las tablas optimiza el rendimiento de las consultas analíticas y la propiedad SCD tipo 2 permite mantener un historial completo de los cambios que ocurren en una dimensión a lo largo del tiempo.
A diferencia de la capa raw, los datos en el contenedor std no se organizan en función de la delegación de origen al estar ya centralizados.
curated
La capa curated es la última etapa antes de que los datos estén listos para su análisis y visualización. Aquí se realizan tareas como la sustitución de claves primarias originales por claves surrogadas, la aplicación de transformaciones de negocio y la selección de columnas relevantes para el análisis.
En esta capa, se asegura que los datos estén estructurados en su forma más eficiente para su explotación en motores analíticos. Además las transformaciones de negocio aplicadas categorizan los datos y añaden valor a los informes.
Similar a la capa std, la capa cuareted mantiene una organización centralizada de los datos. Sin embargo, en esta etapa, los datos se encuentran en su forma más refinada y se almacenan para su acceso y uso inmediato.
Metadatos de Azure SQL
La parametrización del proceso de ETL mediante el uso de metadatos de Azure SQL desempeña un papel crítico en la implementación de este proyecto. En el contexto de la empresa NWS, que opera en tres países con datos altamente heterogéneos y en constante crecimiento, la parametrización se vuelve esencial para garantizar la flexibilidad y la capacidad de adaptación a las cambiantes necesidades de datos. Los metadatos actúan como la columna vertebral del ETL, proporcionando información detallada sobre cada columna, tabla y entidad, así como las transformaciones específicas que deben aplicarse en cada fase del proceso.
Esta estrategia de parametrización no solo simplifica la gestión de datos, sino que también reduce significativamente el riesgo de errores y garantiza la consistencia en todo el flujo de datos. A medida que la empresa continúa creciendo y añadiendo nuevas delegaciones, tablas o nuevas fuentes de datos, los metadatos permiten una expansión eficiente del ETL sin necesidad de reescribir código complejo. Además, ofrecen la capacidad de gestionar dinámicamente el tipo de carga (incremental o completa) de las distintas tablas, así como aplicar transformaciones específicas como, por ejemplo, añadir, eliminar o cambiar el nombre de las columnas.
En resumen, los metadatos de Azure SQL proporcionan la agilidad necesaria para gestionar datos en evolución constante y aseguran que el ETL se adapte sin problemas a las cambiantes necesidades de la empresa, lo que es esencial para el éxito de este proyecto y su futura expansión.
Estructura de la base de metadatos de Azure SQL
Azure SQL es la mejor opción para almacenar y consultar los metadatos en este proyecto principalmente porque ofrece una combinación óptima de costos, integración y facilidad de administración. La información de las distintas entidades se divide en 3 bloques principales:
- Metadatos de tablas
- Metadatos de columnas
- Metadatos de los movimientos del ETL
En los metadatos de tablas se almacena la información de cada tabla en cada delegación y en cada localización a lo largo del ETL de manera independiente, es decir, la tabla «TCLIENTES» almacenada en el origen on-premise de la delegación española tiene un ID distinto al de la tabla «TCLIENTES» de la delegación española almacenada, por ejemplo, en el contenedor raw del Data Lake y a su vez tendrá un ID distinto a la tabla «Clients» de la delegación francesa, almacenada también en el origen on-premise.
En los metadatos de columnas la información se almacena con la misma idea que en los metadatos de tablas, es decir, cada columna de cada tabla y en cada fase del ETL es un registro distinto con su propia ID.
La relación de estas tablas con distintas identidades pero con un destino común se gestiona en los metadatos de los movimentos del ETL. En la fase standardize por ejemplo, las tablas «TCLIENTES», de la delegación de España; «Clients», de la delegación de Francia, y «CLIENTES», de la delegación de Portugal, con distintos IDs pero que referencian una misma entidad, se unen verticalmente para formar la tabla «Clients».
Además también se almacenan la información necesaria para la unión horizontal de dimensiones y hechos y para añadir la propiedad SCD tipo 2 a las dimensiones que la requieran. En el siguiente módulo Transformación y lipieza de datos profundizo algo más en estos procesos.
Limpieza y transformación de los datos
Sabiendo ya la estructura de capas de nuestro Data Lake, la organización de la ingesta de los datos mediante canalizaciones de Synapse y la información disponible en la base de metadatos de Azure SQL para orquestar el ETL podemos adentrarnos en la fase de limpieza y transformación de los datos, que es esencial para garantizar la calidad y coherencia de los datos en todo el proceso. En esta etapa, los datos brutos, almacenados en la capa raw de nuestro Data Lake, se someten a una serie de transformaciones y mejoras que los preparan para su uso en análisis y visualización.
Para madurar los datos y moverlos entre los distintos contenedores del Data Lake utilizaremos cuadernos de Apache Spark orquestados también por los metadatos de Azure SQL y ejecutados por canalizaciones de Synapse Analytics. El ETL en este proyecto está dividido en 4 fases:

El código que ejecuta cada uno de los movimientos y transformaciones de los datos está dividido en 5 cuadernos de Apache Spark:
nb00_ETL_main
Es el cuaderno que ejecuta todo el código del ETL.
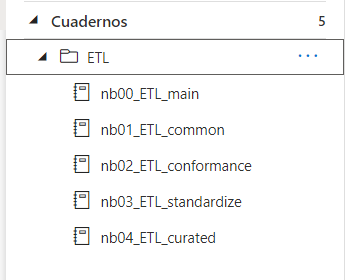
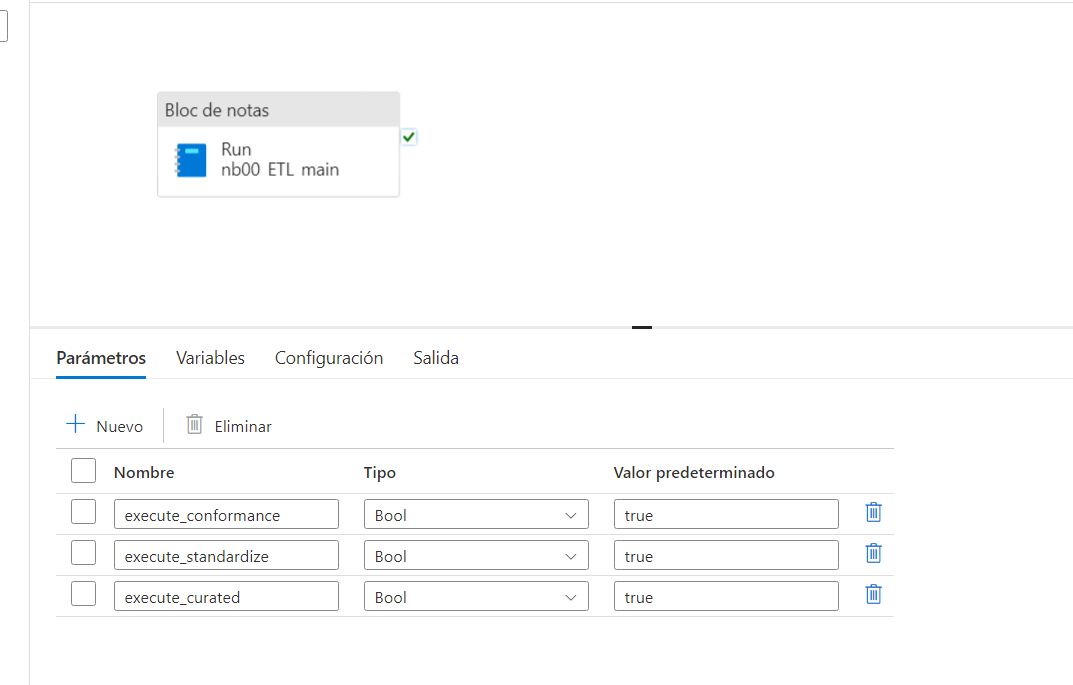
En base a tres parámetros booleanos de base, configurados en la canalización que orquesta todo el ETL, ejecuta el código de los otros 4 cuadernos que explicaremos a continuación (nb01_ETL_common, nb02_ETL_conformance, nb03_ETL_standardize, nb04_ETL_curated) con los métodos que transforman y procesan los datos en base a los metadatos de Azure SQL y las caráctristicas de cada capa del Data Lake.

nb01_ETL_common

Cuaderno que almacena todos los métodos referenciados en las 3 fases del ETL.
- read_SQL_table()
- column_renamer()
- update_LastLoadDate_metadata()
- get_dataframe()
- union_df()
- deduplicate_PKs()
- overwrite_readed_table()
- pk_duplicated()
- update_metadata_in_SQL()
- deduplicate_and_write()
nb02_ETL_conformance

(raw/landing -> raw/conformance)
- Deduplicación de datos
- Unificación de formatos (parquet)
- Información distribuída por delegación (NWS_Spain, NWS_France, NWS_Portugal, Common)

¿Qué hace la función conformance()?
Utiliza los métodos comunes previamente importados para:
- Cargar la información de los métadatos de Auzre SQL en un Dataframe de pyspark
- Iterar los metadatos y obtener la información necesaria para cada tabla
- En base a la información obtenido de los metadatos, leer los datos de landing (Contenedor ADLS)
- Deduplicar y escribir los datos en conformance (Contenedor ADLS)
Output: Dataframe con los metadatos acctualizados y valor booleano que determina si la función se ha ejecutado sin errores.
nb03_ETL_standardize

(raw/conformance -> std)
- Centralización de las delegaciones (Unión vertical de las tablas de las distintas delegaciones, todo pasa a estar en inglés, idioma común)
- Desnormalización de dimensiones y hechos (Unión horizontal de las distintas entidades que forman una misma tabla de dimensiones o hechos en el modelo analítico)
- Se añade la propiedad SCD tipo 2 (Slowly Changing Dimensions) a las dimensiones que lo requieran, según los metadatos de Azure SQL

¿Qué hace la función standardize()?
Utiliza los métodos comunes previamente importados y los métodos propios del cuaderno nb03_ETL_standardize para:
- Cargar la información de los métadatos de Auzre SQL en un Dataframe de pyspark
- Iterar los metadatos y obtener la información necesaria para cada tabla
- En base a la información obtenido de los metadatos, leer los datos de conformance (Contenedor ADLS)
- Unir verticalmente las tablas de las distintas delegaciones y unir horizontalmente las entidades que forman una misma tabla en el modelo analítico.
- Escribir los datos en std (Contenedor ADLS)
Output: Dataframe con los metadatos acctualizados y valor booleano que determina si la función se ha ejecutado sin errores.
nb04_ETL_curated

(std -> curated)
- Sustitución de PK por SK
- Aplicación de transformaciones de negocio
- Seleccionar únicamente las columnas que aportan valor anlítico

¿Qué hace la función curated()?
Utiliza los métodos comunes previamente importados y los métodos propios del cuaderno nb04_ETL_curated para:
- Cargar la información de los métadatos de Auzre SQL en un Dataframe de pyspark
- Iterar los metadatos y obtener la información necesaria para cada tabla
- En base a la información obtenido de los metadatos, leer los datos de std (Contenedor ADLS)
- Sustituir PK por SK y aplicar transformaciones de negocio
- Escribir los datos en curated (Contenedor ADLS)
Output: Dataframe con los metadatos acctualizados y valor booleano que determina si la función se ha ejecutado sin errores.
Plataforma de visualización
La unificación de la plataforma de visualización de los datos fué un requisto fundamental cuándo planteamos la remodelación de la arquitectura de la empresa NWS. Al tener los datos almacenados y modelados en un repositorio centralizado de los datos, el Data Lake en este caso, tenemos una única versión de la verdad a la que nos podemos conectar mediante Power BI para realizar informes que den respuesta a las preguntas de negocio de la empresa.
Además, esta centralización de la información nos permite realizar análisis globales de toda la empresa que antes de la remodelación de la arquitectura eran prácticamente imposibles de hacer, ya que cada delegación desarrollaba informes independientes con sus propios datos y sin seguir estándares comunes.
Power BI, como herramienta de visualización elegida, ofrece una serie de ventajas notables. Su estrecha integración con Azure facilita la conexión a los datos almacenados en el Data Lake y en la base de metadatos de Azure SQL. Además, Power BI es altamente intuitivo y permite a los usuarios crear informes interactivos y paneles de control personalizados sin necesidad de habilidades de programación avanzadas. Esto democratiza el acceso a los datos y capacita a los usuarios de negocio para explorar y analizar la información de manera autónoma.
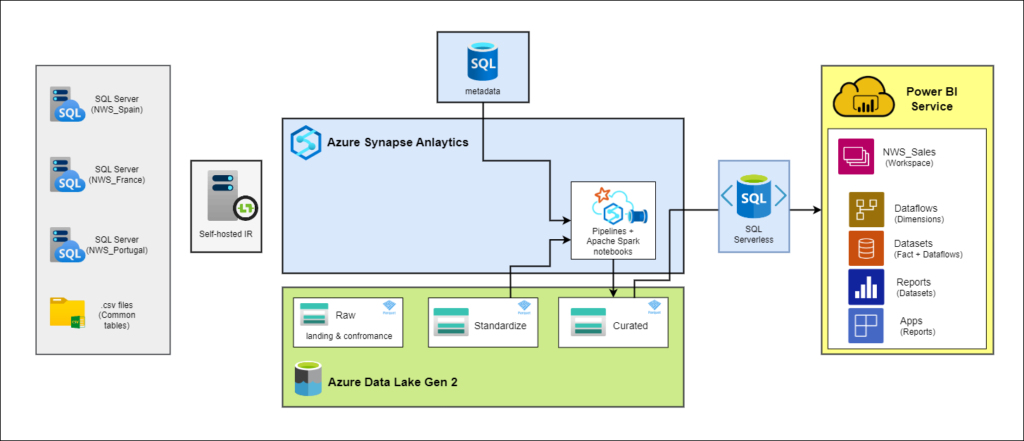
Conexión con SQL Serverless
La herrmienta elegida para conectar la información almacenada en ficheros en nuestro Data Lake con Power BI es SQL Serverless. Estas son las principales ventajas que aporta esta tecnología:
Optimización de costos: Al eliminar la necesidad de mantener servidores provisionados, pagamos únicamente por lo que consultamos.
Escalabilidad Automática: La escalabilidad automática de SQL Serverless se adapta de forma dinámica a las necesidades de nuestras consultas, sin intervención manual. Esta característica es crucial en un entorno Lakehouse, donde los volúmenes de datos pueden variar ampliamente con el tiempo, asegurando que siempre tengamos la potencia de cómputo necesaria.
Integración Fluida con Power BI: SQL Serverless se integra de manera nativa con Power BI, simplificando la conexión entre nuestros conjuntos de datos y nuestras visualizaciones. Esto reduce la complejidad de la configuración y la administración de las conexiones de datos.
Seguridad y Control de Acceso: La solución SQL Serverless proporciona robustas capacidades de seguridad, incluyendo autenticación y autorización basadas en roles. Esto nos otorga un control total sobre quién puede acceder a los datos y qué consultas pueden ejecutarse, garantizando la confidencialidad y la integridad de nuestros activos de datos.
- Capacidad de caché de Azure: La implementación de vistas de SQL Serverless permite mejorar aún más el rendimiento al aprovechar la capacidad de caché de Azure. Esto significa que las consultas frecuentes pueden beneficiarse de datos previamente almacenados en caché, acelerando las respuestas y reduciendo la latencia en la visualización de datos.
En resumen, al utilizar SQL Serverless y aprovechar la capacidad de caché de Azure en una arquitectura Lakehouse para conectar los datos del Data Lake a los datasets de Power BI, puedes optimizar costos, mejorar el rendimiento y garantizar la seguridad de los datos, al mismo tiempo que simplificas la administración de conexiones de datos y aceleras las respuestas en la visualización de datos frecuentes.
Organización del área de trabajo
La organización del área de trabajo en la plataforma de visualización desempeña un papel crucial en la eficiencia y la colaboración entre los equipos de análisis. En este proyecto, se ha implementado una estructura de trabajo que se basa en la centralización de dimensiones y la conexión directa de los hechos a los datasets, lo que aporta diversas ventajas significativas:
Centralización de Dimensiones: En lugar de replicar las dimensiones en cada informe o conjunto de datos, se ha centralizado la gestión de dimensiones en un único dataflow. Esto asegura que todas las visualizaciones y análisis utilicen las mismas definiciones de dimensiones, lo que evita inconsistencias y garantiza la coherencia en los informes. Además, cualquier actualización en las dimensiones se refleja de manera automática en todos los informes que las utilizan, lo que simplifica la administración y el mantenimiento.
Conexión Directa de Hechos: Los hechos, que representan los datos numéricos clave, están conectados directamente a los datasets de Power BI. Esta conexión directa permite un acceso rápido y eficiente a los datos de los hechos, sin la necesidad de intermediarios o transformaciones complejas. Los usuarios pueden crear análisis y métricas personalizadas de manera ágil, lo que acelera el proceso de generación de información y toma de decisiones.
Mantenimiento Simplificado: Al centralizar las dimensiones y conectar directamente los hechos, la plataforma de visualización se vuelve más fácil de mantener y actualizar. Los cambios en las estructuras de dimensiones o en los datos de los hechos se gestionan de manera centralizada, lo que reduce el riesgo de errores y garantiza que todos los informes estén siempre actualizados y en consonancia con los requisitos del negocio.
Mayor Colaboración: La organización del área de trabajo fomenta la colaboración entre los equipos de análisis, ya que todos trabajan con un conjunto de datos coherente y actualizado. Los analistas pueden compartir fácilmente sus informes y paneles con otros usuarios, promoviendo una comprensión común de los datos y facilitando la colaboración en proyectos analíticos.
En resumen, la organización del área de trabajo en esta plataforma de visualización se basa en la centralización de dimensiones y la conexión directa de hechos a datasets, lo que simplifica el mantenimiento, mejora la consistencia de los informes y fomenta la colaboración entre los equipos de análisis. Esta estructura eficiente contribuye a la agilidad y la eficacia en la explotación de datos para la toma de decisiones empresariales.
Informe de ventas
Por poner un ejemplo de los informes desarrollados en Power BI, analizaremos el informe de ventas que hemos creado en este proyecto en el que se analizan las ventas de la empresa NWS desde diferentes prismas. Vamos a ir comentando una a una las distintas páginas y algunas de sus funcionalidades.
Esta página sirve de índice para acceder a los distintos análisis del informe. Además en la zona inferior te indica el nivel de acceso RLS que se te ha otorgado. Este informe utiliza un RLS dinámico que utiliza el método USERPRINCIPALNAME() para detectar tu usario y, en base a una tabla en la que está especificado el acceso de cada usuario a cada delegación, filtra la información del dataset.

Esta página compara las ventas, costes, beneficios y cantidades vendidas de el año seleccionado con el año anterior.

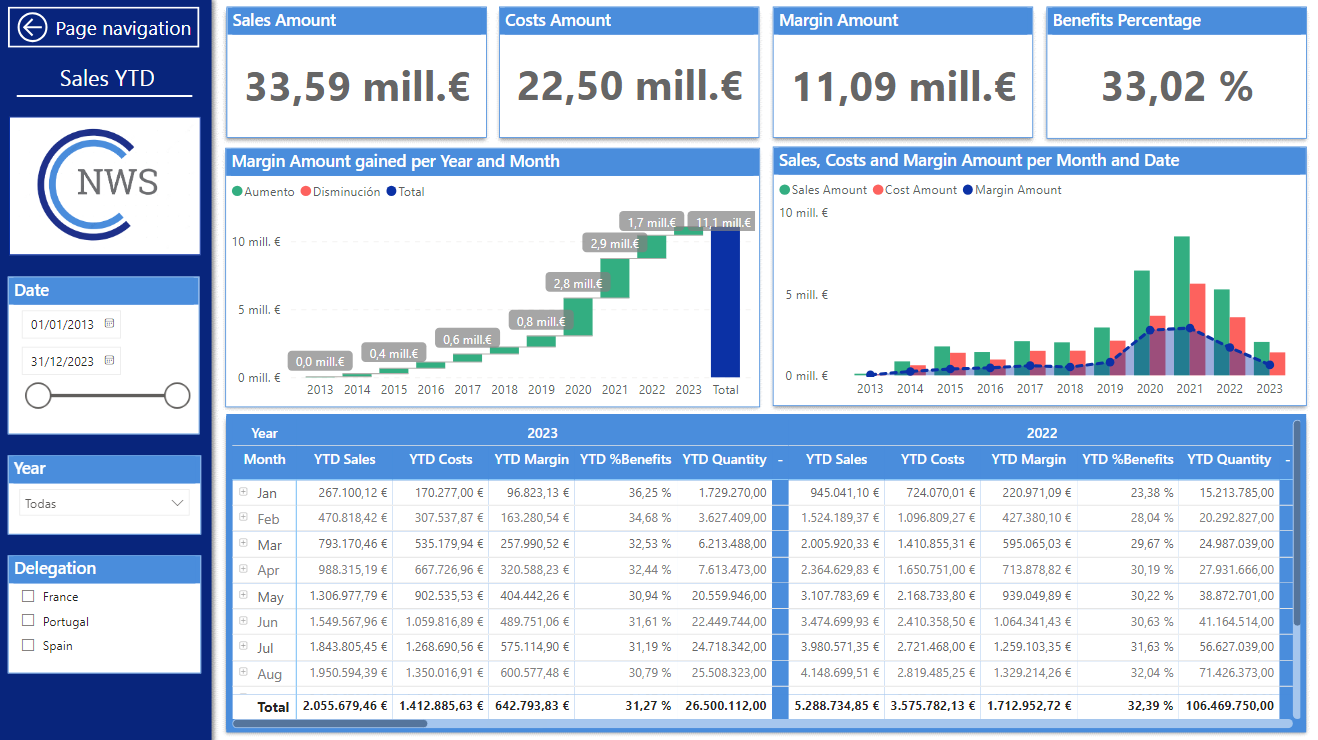
Esta página representa el acumulado de ventas, costes, beneficios y cantidades vendidas a nivel de año, mes y día.
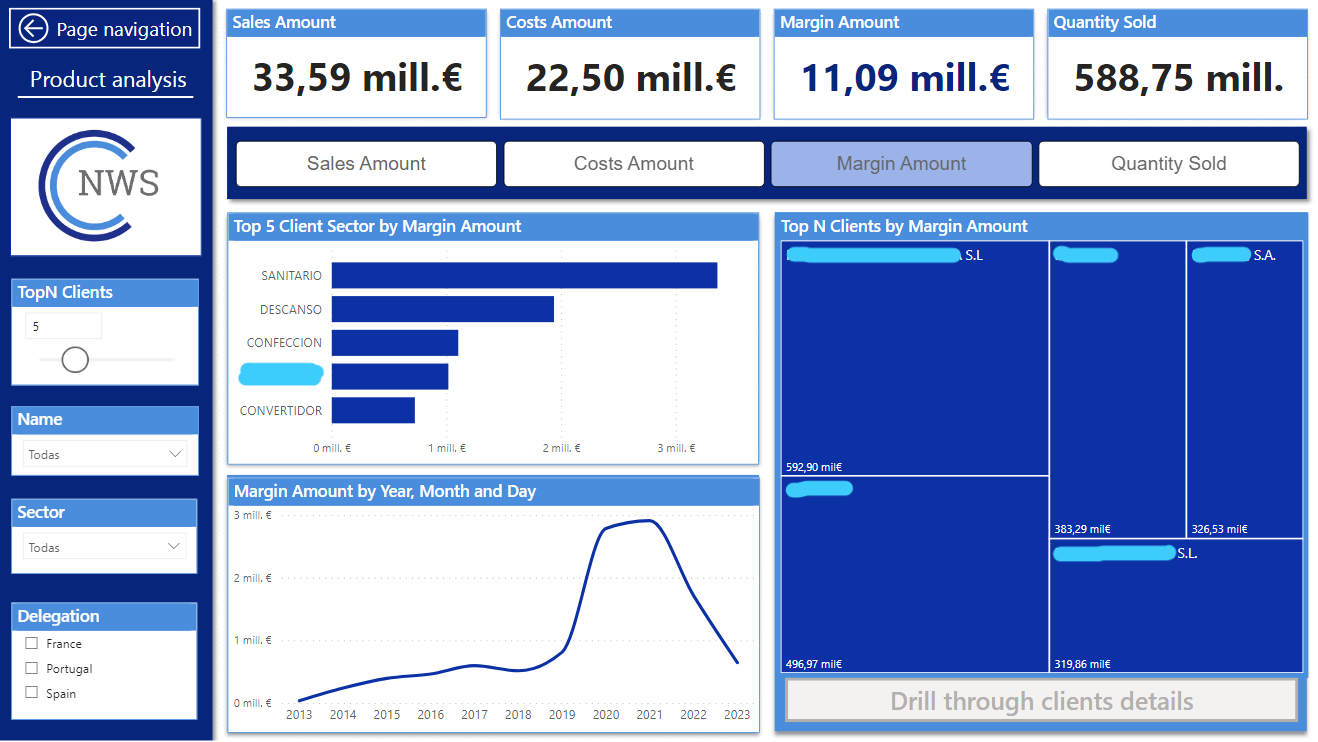
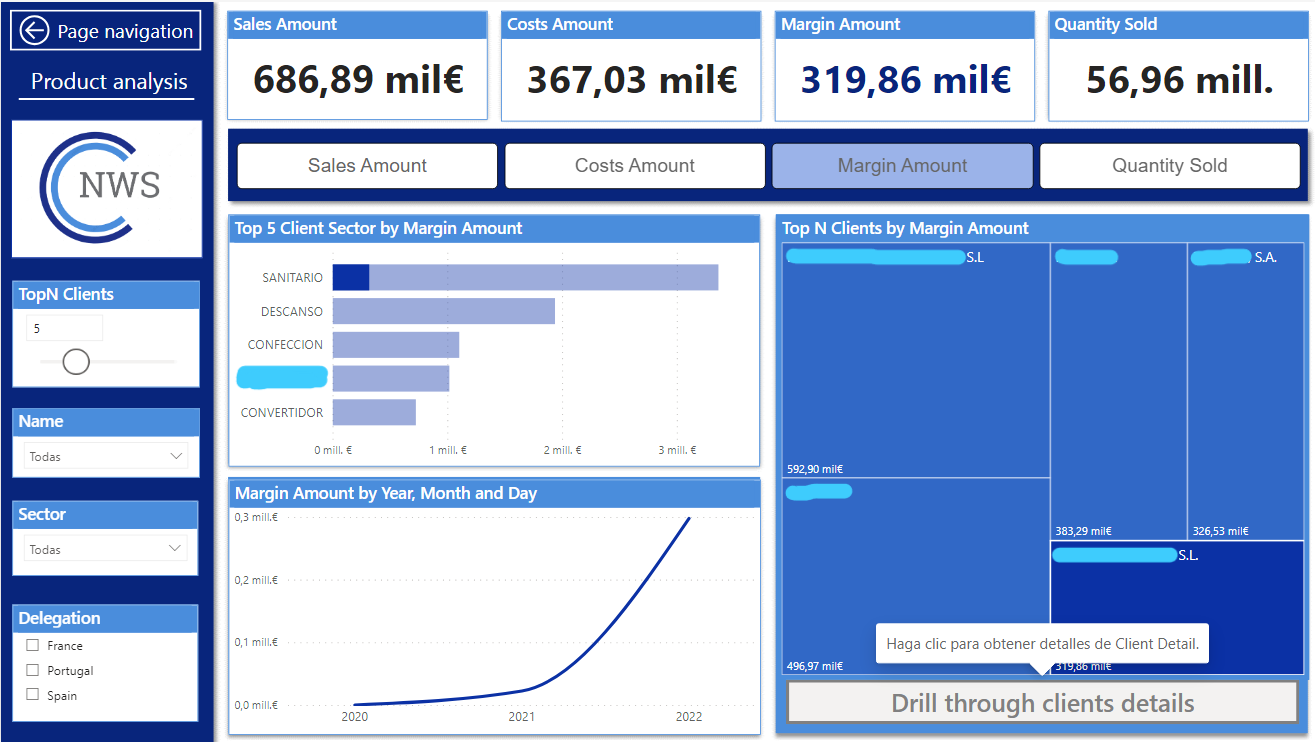
Esta página analiza las ventas, cosetes, beneficios y cantidades vendidas por producto y por familia de producto dependiendo de la medida que se haya seleccionado en el slicer superior. Además en el slicer de la izquierda «TopN Products» puedes elegir la cantidad de productos que quieres que se muestre.
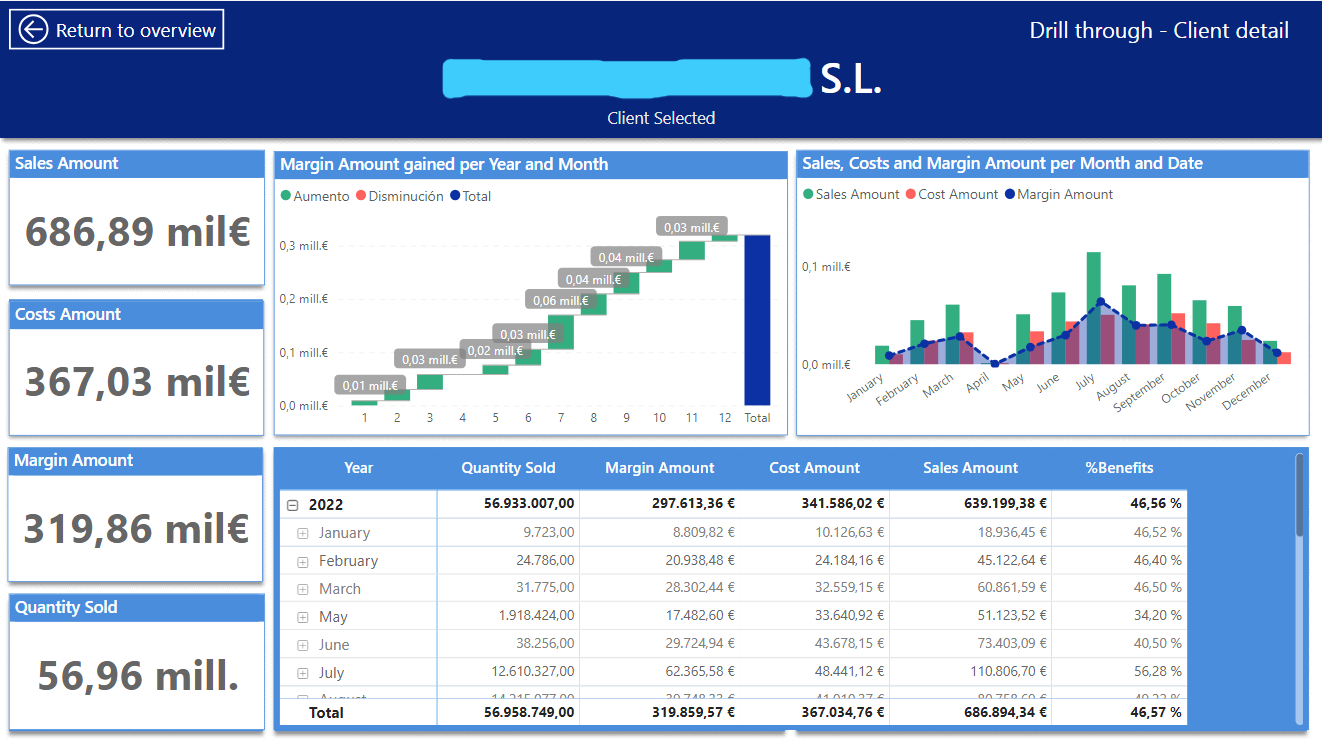
Al seleccionar cualquier producto se activa el botón de drill-trough que al clickearlo te redirige a la página de detalle de el producto elegido.
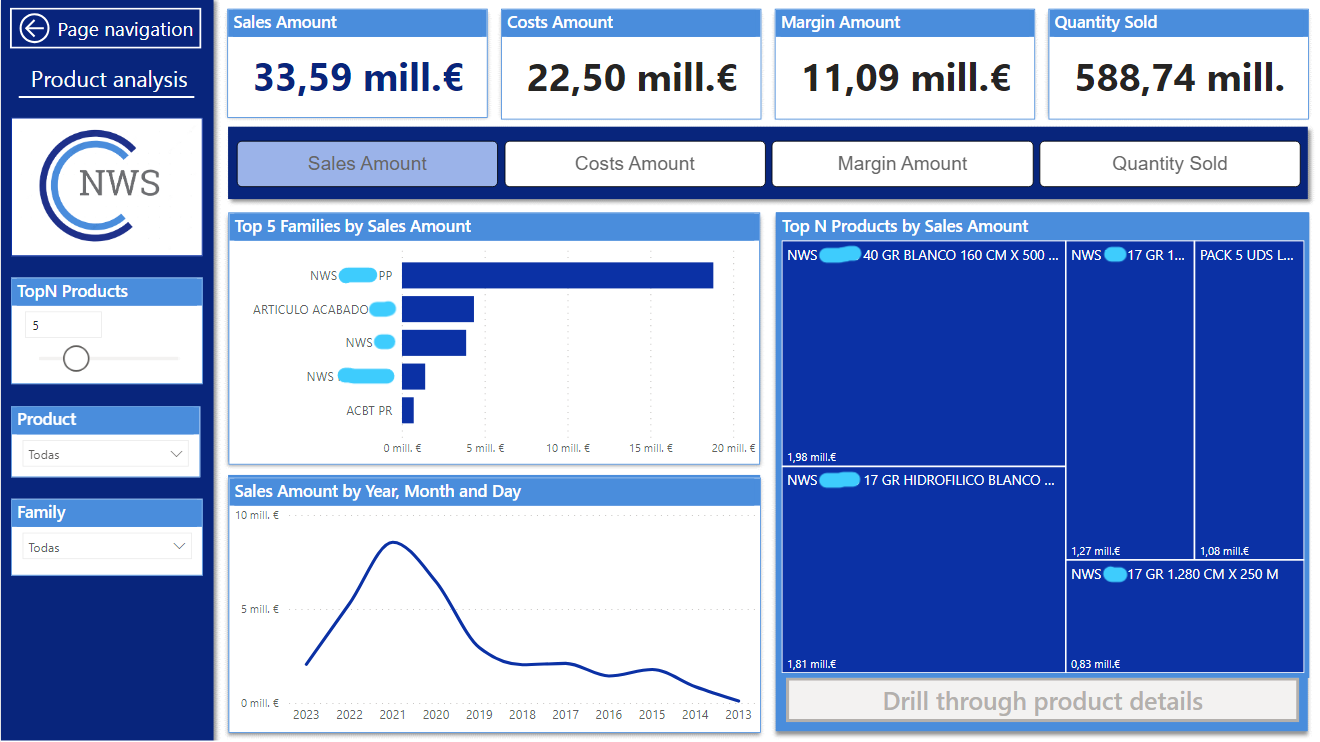

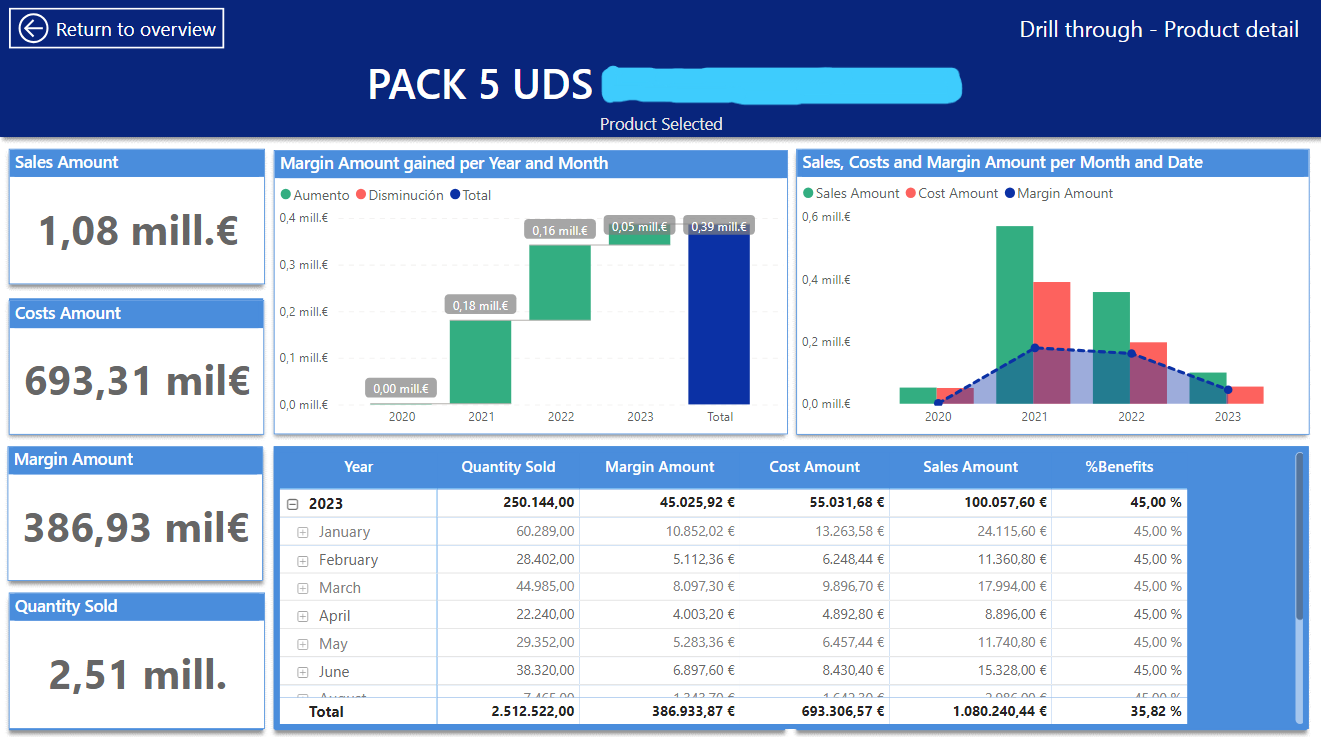
Funcionan igual que el análisis por producto